📚 HTML 考題小舖
📖 iPAS AI應用規劃師-初級能力鑑定 精選模擬試題/重點整理(免費試閱)
📖 iPAS AI應用規劃師-中級能力鑑定 精選模擬試題/重點整理(免費試閱)
📖 2025年最新版 Azure AI900 微軟中文版題庫【免費試閱】
📖 2025年最新版微軟證照題庫系列【AZ-900】【AI-102】【AI-900】【DP-900】【PL-900】等
初級 AI應用規劃師 經典回顧卷002
2025/05/03 (第2場考試重點整理)
評鑑主題 (點擊篩選)
L112 資料處理與分析概念
★★★☆☆
詞幹提取 (Stemming) vs 詞形還原 (Lemmatization)
核心概念
兩者皆為自然語言處理(NLP)中的詞語正規化技術,目的為將詞語還原至基本或詞根形式。主要區別在於處理方式與結果精確度:
- 詞幹提取 (Stemming): 通常基於規則,移除詞語的後綴或前綴。速度較快,但結果可能不是一個實際存在的詞 (例如 "studies", "studying" 可能都變成 "studi")。
- 詞形還原 (Lemmatization): 考慮詞性 (Part-of-Speech) 和詞彙表(字典),將詞語還原為其字典中的基本形式(詞元, lemma)。結果更準確(如 "studies", "studying" 都還原為 "study"),但需要詞典且速度較慢。
選擇考量
若應用對速度要求高於精確度(如訊息檢索),可選詞幹提取;若需要高精確度的語義分析(如機器翻譯、問答系統),則詞形還原更佳。
L113 機器學習概念
★★★★★
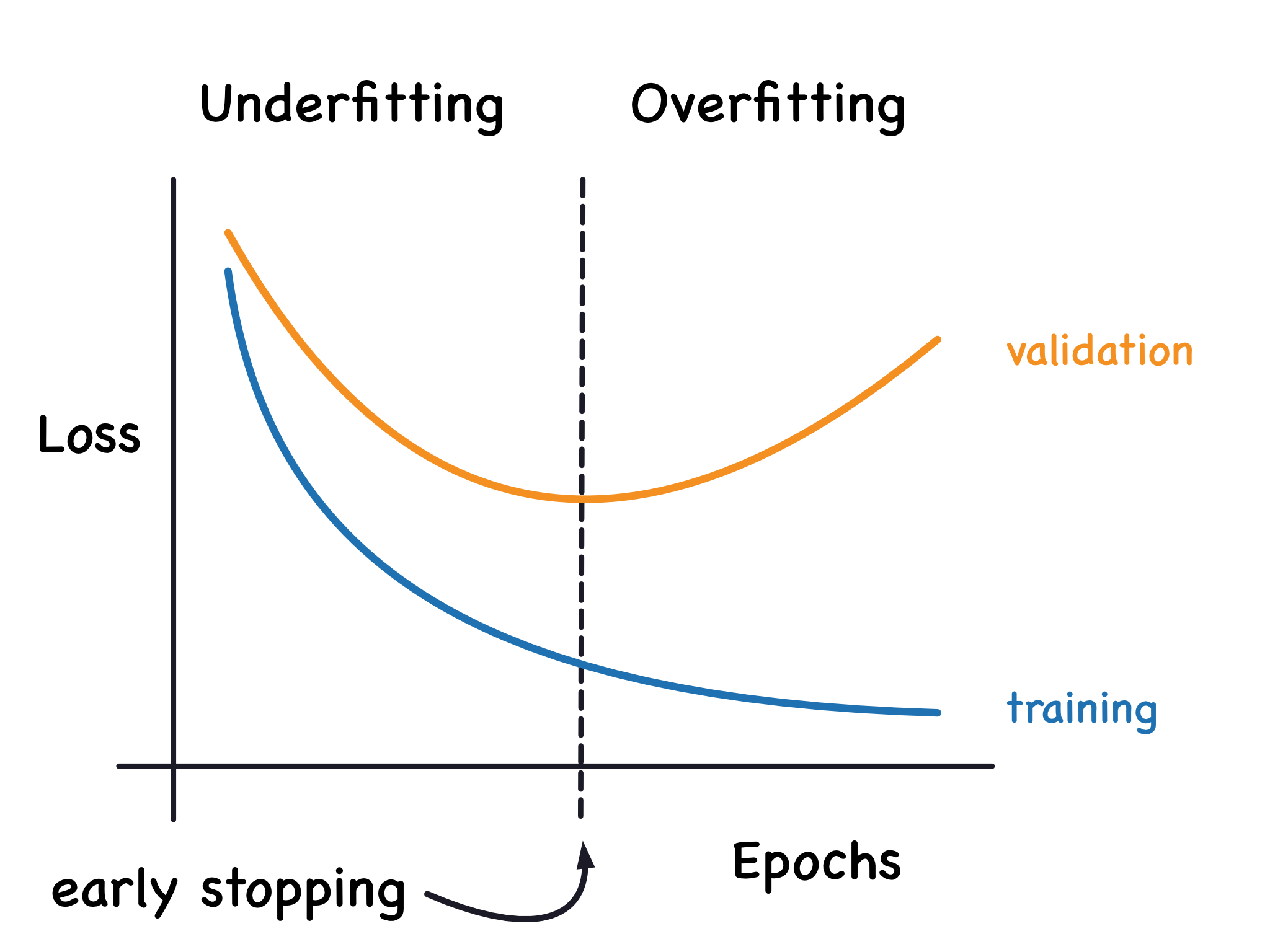
過擬合 (Overfitting) 與 低度擬合 (Underfitting)
核心概念
過擬合 (Overfitting) 指的是模型在訓練集上表現良好,但因過度學習了訓練數據中的雜訊和細節,導致在未見過的新數據(驗證集或測試集)上表現較差,泛化能力不足。
低度擬合 (Underfitting) 則是指模型過於簡單,無法充分學習訓練數據中的模式,導致在訓練集和新數據上表現都不佳。
低度擬合 (Underfitting) 則是指模型過於簡單,無法充分學習訓練數據中的模式,導致在訓練集和新數據上表現都不佳。
與偏差/變異的關係
過擬合通常表現為高變異 (Variance) 和低偏差 (Bias);低度擬合則通常表現為高偏差和低變異。理想的模型應在兩者間取得平衡(Bias-Variance Tradeoff)。增加模型複雜度通常會降低偏差但提高變異。
常見解決方案
降低過擬合: 增加訓練數據量、數據增強、降低模型複雜度(如減少層數/節點)、正則化 (Regularization, 如L1,L2)、Dropout、交叉驗證 (Cross-validation)、早停法 (Early Stopping)。
解決低度擬合: 增加模型複雜度(如增加特徵、增加模型層數)、減少正則化程度、特徵工程 (Feature Engineering)。
解決低度擬合: 增加模型複雜度(如增加特徵、增加模型層數)、減少正則化程度、特徵工程 (Feature Engineering)。
L113 機器學習概念
★★★★☆
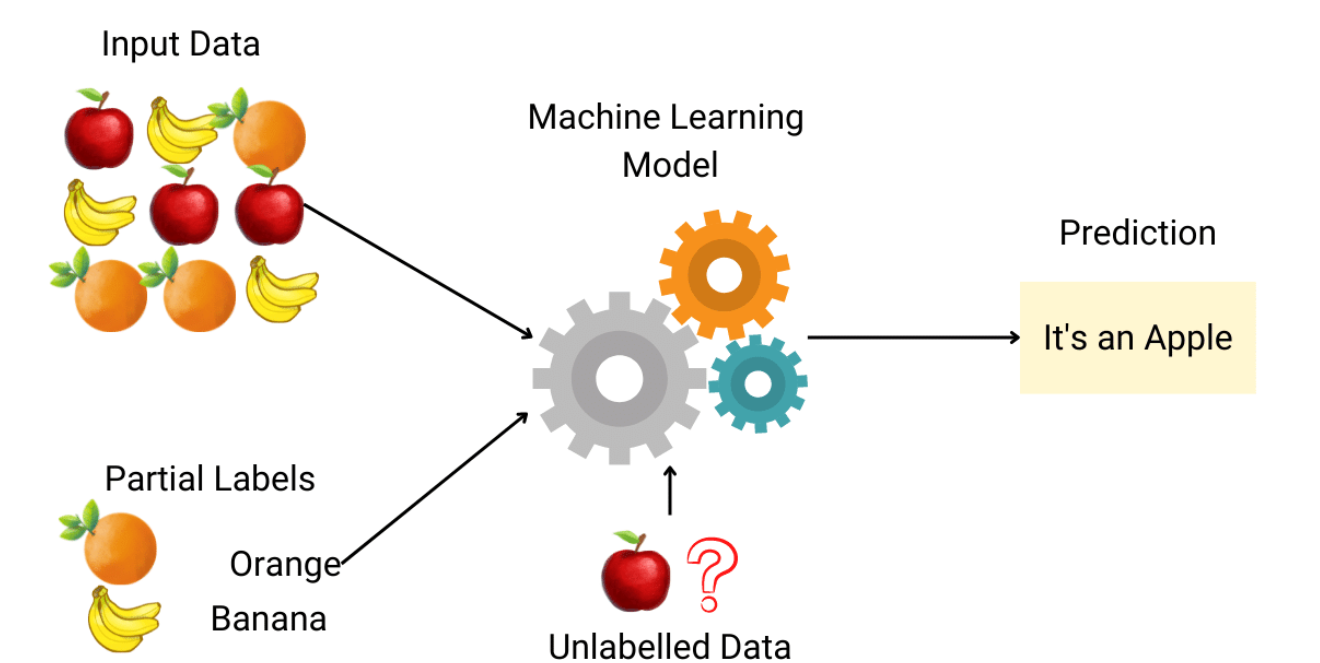
半監督學習 (Semi-supervised Learning)
核心概念
半監督學習是機器學習的一個分支,其訓練數據包含一小部分有標記的數據和大量未標記的數據。目標是利用未標記數據中蘊含的結構訊息來輔助學習,以達到比僅使用少量標記數據更好的模型性能。
運作方式
常見方法包括:
- 自訓練 (Self-training): 先用標記數據訓練一個初始模型,然後用該模型預測未標記數據,將置信度高的預測結果及其偽標籤加入訓練集,反覆迭代。
- 生成模型 (Generative Models): 嘗試學習數據的潛在分佈,未標記數據有助於更準確地估計分佈。
- 圖基學習 (Graph-based Methods): 將所有數據(標記和未標記)構建成一個圖,通過圖上的標籤傳播來預測未標記數據。
適用場景
當獲取大量未標記數據相對容易,但獲取標記數據成本高昂或耗時的情況下特別有用。例如:網頁分類、語音識別、生物訊息學中的蛋白質功能預測等。
L111 人工智慧概念
★★★★★
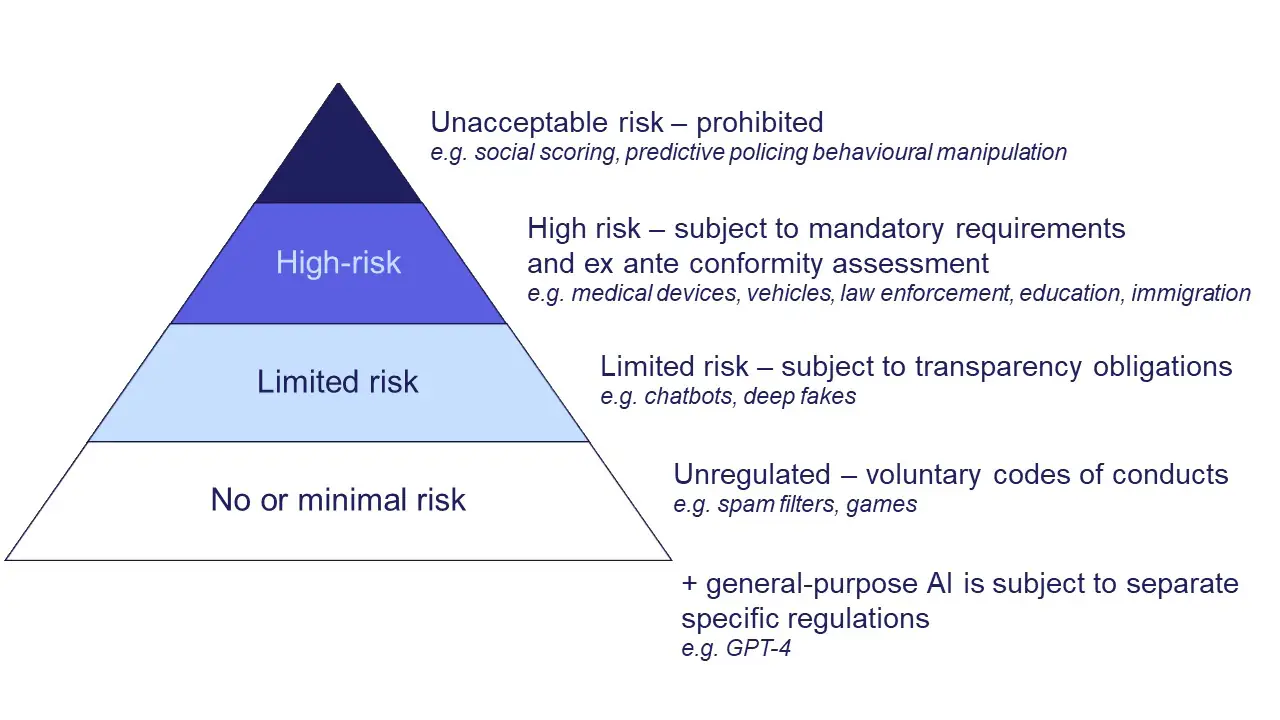
歐盟 AI 法案 (EU AI Act) 風險分級
核心概念
《EU AI Act》是全球首部針對AI的全面性法律框架,其核心是基於風險的方法,將AI系統分為四個風險等級,並施加不同程度的監管要求:
- 不可接受風險 (Unacceptable Risk): 原則上禁止。此類AI對基本權利構成威脅。例子:政府進行的社會評分、利用弱勢群體弱點的操縱性系統、公共場所的即時遠程生物識別(執法等少數例外)。
- 高風險 (High Risk): 需遵守嚴格的合規要求才能上市或投入使用。包括:
- 受現有產品安全法規監管的AI系統(如玩具、航空、汽車、醫療器械的安全組件)。
- 附件三列出的特定領域AI系統:生物識別、關鍵基礎設施管理、教育與職業培訓、就業與勞工管理(如招聘、績效評估、出勤監控)、基本服務(公共/私人)的獲取(如信用評分、福利資格)、執法、移民/邊境管制、司法與民主程序管理。
- 有限風險 (Limited Risk): 主要要求履行透明度義務,讓用戶知道他們在與AI互動。例子:聊天機器人(Chatbot)、情緒識別系統、生物特徵分類系統、深度偽造(Deepfake)(需標示AI生成)。
- 最小風險 (Minimal Risk): 大多數現有AI系統屬於此類,風險極低或沒有。例子:AI垃圾郵件過濾器、電子遊戲中的AI、不涉及敏感決策的AI語音助理(如查詢天氣、食譜)。此類系統可自由使用,鼓勵遵守自願性行為準則。
L113 機器學習概念
★★★★★
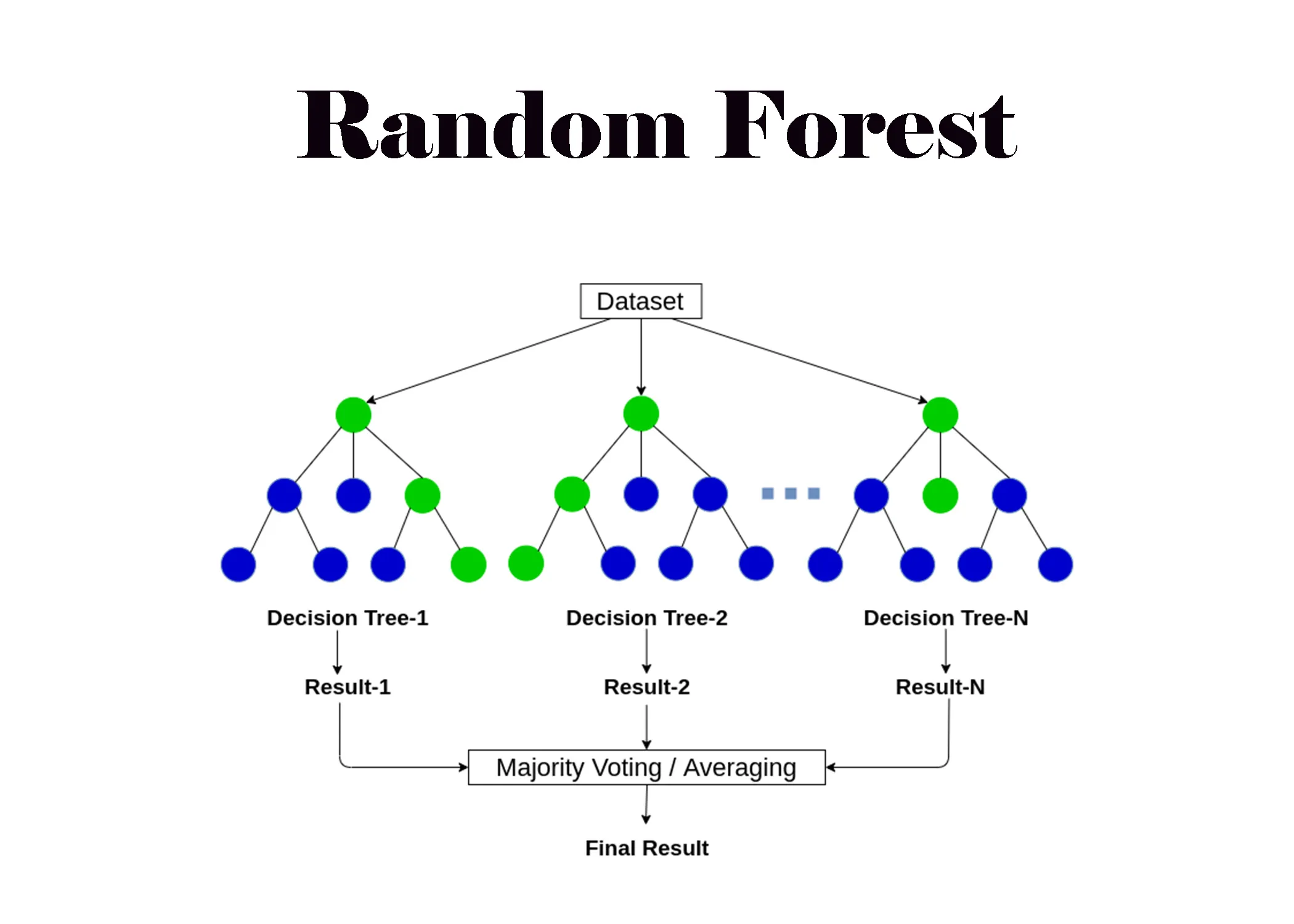
隨機森林 (Random Forest)
原理
隨機森林是一種強大的集成學習 (Ensemble Learning)技術,它通過構建多棵決策樹 (Decision Trees)並匯總它們的預測結果來提高分類 (Classification)和迴歸 (Regression)任務的準確性和穩定性。其核心機制包括:
- Bootstrap 抽樣 (Bagging): 對於每棵樹的訓練,都是從原始訓練數據集中進行有放回的隨機抽樣 (Bootstrap sampling),創建一個與原數據集大小相同的訓練子集。這意味著某些樣本可能被多次選中,而另一些可能一次也未被選中。
- 隨機特徵選擇 (Random Feature Selection): 在構建每棵決策樹的過程中,當需要在某個節點進行分裂時,不是考慮所有可用特徵,而是從中隨機選擇一個特徵子集(例如,總特徵數的平方根),然後再從這個子集中選擇最佳的分裂特徵。
預測方式
對於分類任務,隨機森林的最終預測結果由所有決策樹投票決定(選擇得票最多的類別)。對於迴歸任務,最終預測結果是所有決策樹預測值的平均值。
優點與應用
- 優點: 高準確率;良好的抗過擬合性能;能處理高維數據和大量樣本;能夠評估特徵的重要性;對缺失數據具有一定的魯棒性。
- 應用: 廣泛應用於金融(信用評分、欺詐檢測)、醫療(疾病預測、基因數據分析)、遙感圖像分類、推薦系統等眾多領域。
L113 機器學習概念
★★★★☆
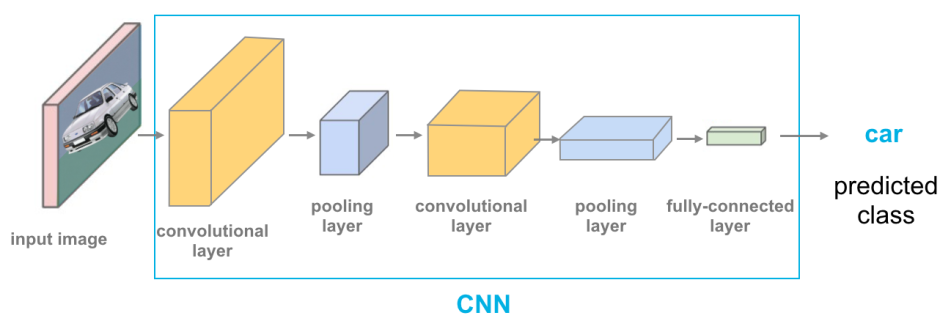
卷積神經網路 (Convolutional Neural Network, CNN)
核心概念
CNN 是一種特別擅長處理網格結構數據(如圖像)的深度學習模型。其關鍵在於卷積層 (Convolutional Layer),它使用卷積核(Kernel / Filter)在輸入數據上滑動,提取局部特徵(如邊緣、紋理)。
其他重要組成部分包括:
其他重要組成部分包括:
- 池化層 (Pooling Layer): 降低數據維度(降採樣),減少計算量,提取最顯著特徵,提高模型的平移不變性。常見的有最大池化 (Max Pooling) 和平均池化 (Average Pooling)。
- 全連接層 (Fully Connected Layer): 通常位於網路末端,將前面層提取的特徵進行組合,用於最終的分類或迴歸任務。
- 激活函數 (Activation Function): 如 ReLU,引入非線性,使網路能學習更複雜的模式。
主要應用
圖像辨識、物體偵測、圖像分割、人臉辨識、醫學影像分析、自然語言處理(部分任務)等。
L113 機器學習概念
★★★☆☆
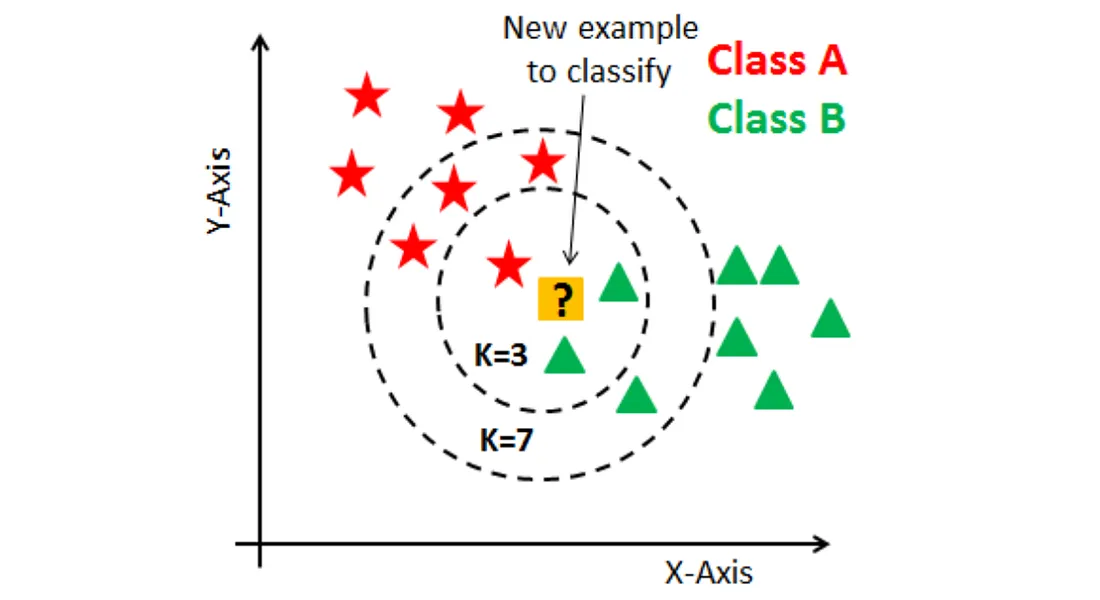
KNN (K-最近鄰演算法)
原理
KNN (K-Nearest Neighbors) 是一種簡單且直觀的監督式學習演算法,可用於分類和迴歸任務。它基於「物以類聚」的思想,屬於實例式學習(或稱惰性學習),即它不建立顯式的模型,而是在預測階段才進行計算。
判別原理:
判別原理:
- 計算新數據點(需要預測的點)與訓練集中所有數據點之間的距離(常用歐氏距離)。
- 選取距離新數據點最近的 K 個訓練數據點(即 K 個最近鄰)。
- 分類任務: 將新數據點的類別預測為這 K 個鄰居中出現次數最多的類別(多數決投票)。
- 迴歸任務: 將新數據點的值預測為這 K 個鄰居值的平均值(或加權平均值、中位數)。
L114 鑑別式 AI 與生成式 AI 概念
★★★★☆
生成式AI (GAI) vs 鑑別式AI (DAI)
核心區別
兩者是機器學習模型的兩大類別,主要區別在於學習目標和任務:
- 鑑別式AI (Discriminative AI): 學習輸入特徵 (X) 與輸出標籤 (Y) 之間的條件機率 P(Y|X) 或直接學習一個決策邊界。目標是區分不同的類別或預測一個值。它不關心數據是如何生成的。
例子: 邏輯迴歸、SVM、決策樹(用於分類時)、傳統的神經網路(用於分類/迴歸)。 - 生成式AI (Generative AI): 學習數據的聯合機率分佈 P(X,Y) 或輸入特徵的邊際機率分佈 P(X)。目標是理解數據是如何生成的,並能夠產生新的、類似的數據樣本。
例子: GAN(生成對抗網路)、VAE(變分自編碼器)、樸素貝葉斯 (Naive Bayes)、隱馬可夫模型 (HMM)、Transformer(用於生成任務時)。
應用場景
DAI: 分類(如垃圾郵件檢測、圖像識別)、迴歸(如房價預測)。
GAI: 內容生成(文本、圖像、音樂)、數據增強、異常檢測(通過判斷新數據是否符合學習到的分佈)、密度估計。
GAI: 內容生成(文本、圖像、音樂)、數據增強、異常檢測(通過判斷新數據是否符合學習到的分佈)、密度估計。
共同運用
可以結合使用,例如:用GAI生成合成數據來擴充數據量不足的類別,然後用DAI在更平衡的數據集上進行訓練,以提高分類模型的性能。
L113 機器學習概念
★★★☆☆
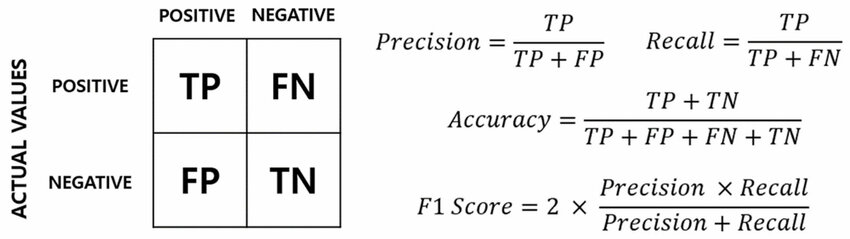
混淆矩陣 (Confusion Matrix)
核心概念
混淆矩陣是用於評估分類模型性能的一種表格。它將模型的預測結果與實際的真實標籤進行比較,並將結果歸納為四種類型:
- 真陽性 (TP - True Positive): 實際為正例,模型也預測為正例。
- 真陰性 (TN - True Negative): 實際為反例,模型也預測為反例。
- 偽陽性 (FP - False Positive): 實際為反例,但模型預測為正例(Type I Error)。
- 偽陰性 (FN - False Negative): 實際為正例,但模型預測為反例(Type II Error)。
L113 機器學習概念
★★★★☆
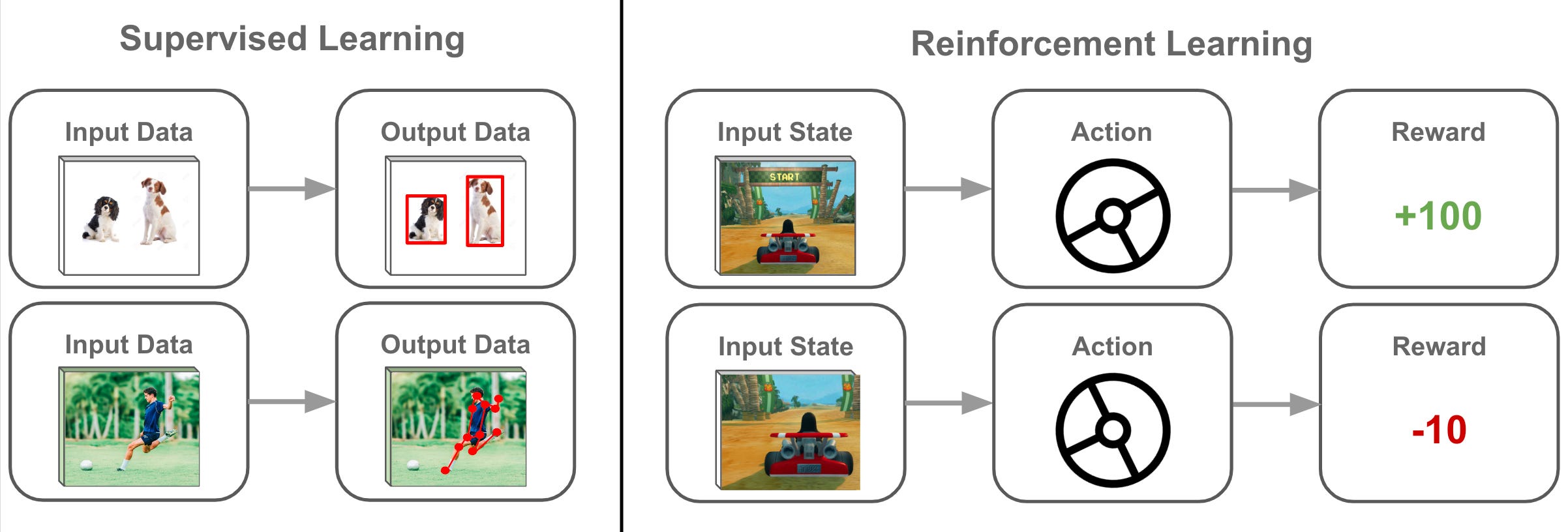
強化學習 (Reinforcement Learning, RL)
核心概念
強化學習是機器學習的三大範式之一(另兩者為監督式和非監督式)。它關注的是智能體 (Agent) 如何在一個環境 (Environment) 中採取一系列行動 (Action),以最大化長期累積的獎勵 (Reward)。
學習過程是通過試錯 (Trial-and-Error) 進行的,智能體根據行動後獲得的獎勵(或懲罰)來調整其策略 (Policy),即在特定狀態 (State) 下選擇何種行動的規則。
學習過程是通過試錯 (Trial-and-Error) 進行的,智能體根據行動後獲得的獎勵(或懲罰)來調整其策略 (Policy),即在特定狀態 (State) 下選擇何種行動的規則。
關鍵要素
- 智能體 (Agent): 學習者和決策者。
- 環境 (Environment): 智能體互動的外部世界。
- 狀態 (State): 環境當前的狀況。
- 行動 (Action): 智能體可以採取的動作。
- 獎勵 (Reward): 環境對智能體行動的回饋信號,用於評估行動的好壞。
- 策略 (Policy): 智能體從狀態到行動的映射規則。
應用
特別適合解決需要序貫決策(Sequential Decision Making)的問題。例如:遊戲AI(如圍棋AlphaGo、電子遊戲)、機器人控制(如學習行走、抓取)、自動駕駛(決策制定)、推薦系統、資源管理等。
L114 鑑別式 AI 與生成式 AI 概念
★★★★☆
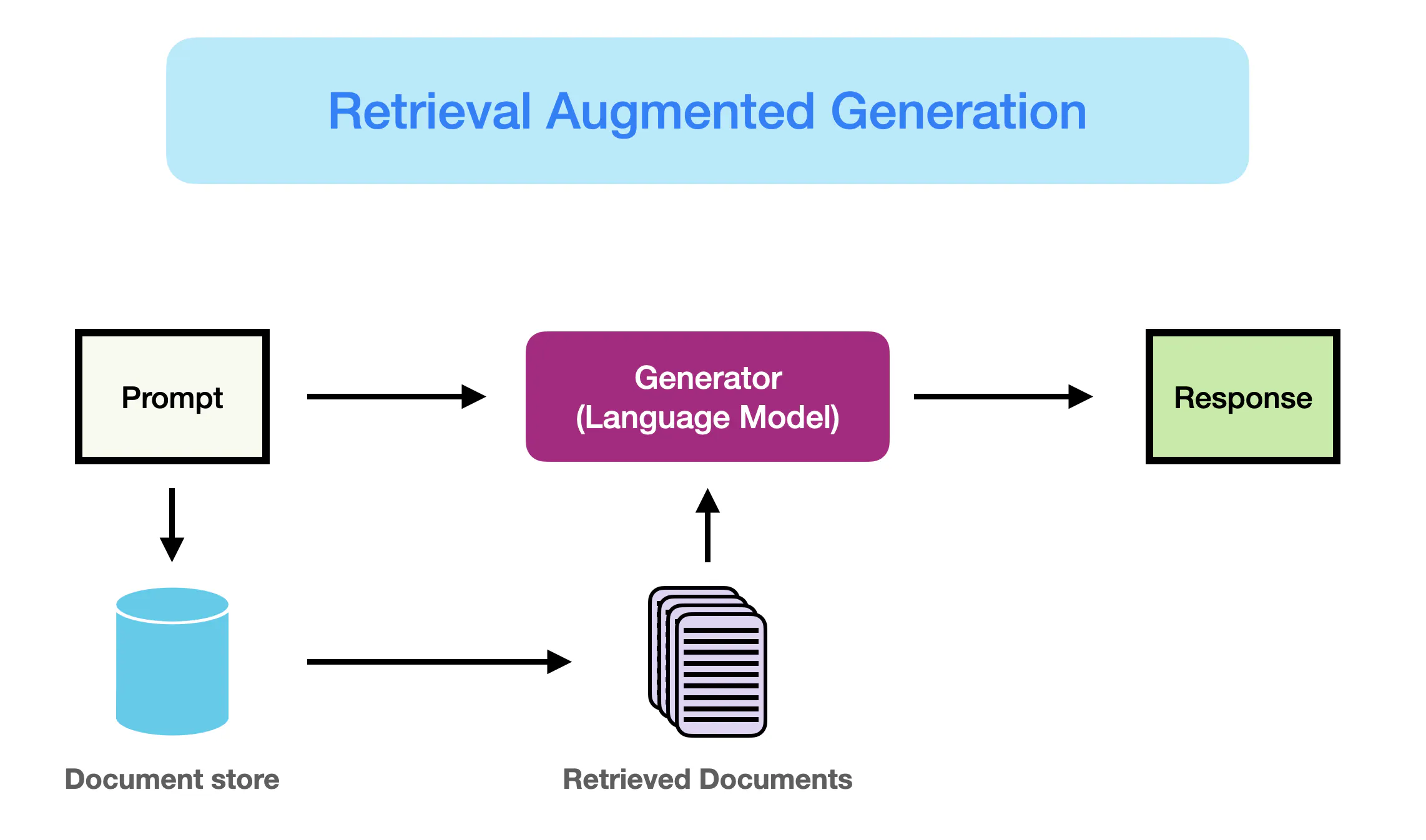
RAG (檢索增強生成)
核心概念
RAG (Retrieval-Augmented Generation) 是一種結合了資訊檢索 (Information Retrieval) 和大型語言模型 (LLM) 文本生成能力的技術框架。
其工作流程通常是:
其工作流程通常是:
- 當收到用戶的提示 (Prompt) 時,首先使用該提示作為查詢 (Query) 去一個外部知識庫(如文檔數據庫、向量數據庫)中檢索 (Retrieve) 最相關的訊息片段。
- 將檢索到的相關訊息與原始提示結合,形成一個增強後的提示 (Augmented Prompt)。
- 將這個增強後的提示輸入到LLM中,讓LLM基於這些訊息生成 (Generate) 最終的回應。
目的與優勢
- 減少幻覺 (Hallucination) 和提高事實準確性:讓LLM的回答基於具體的、可驗證的外部知識。
- 利用最新或特定領域的知識:使LLM能夠回答其訓練數據中未包含或已過時的資訊。
- 提高透明度和可追溯性:可以引用檢索到的來源,讓用戶了解答案依據。
RAG vs 微調 (Fine-tuning)
RAG和微調都是增強LLM能力的方法,但側重點不同:
- 速度與成本: RAG通常更快、成本更低,因為它不需要重新訓練龐大的LLM,只需構建和維護檢索庫。
- 知識更新: RAG更容易更新知識,只需更新外部知識庫即可。
- 知識內化程度: 微調是將特定知識“內化”到模型參數中,可能在某些任務上(如學習特定風格或術語)更深入;RAG則是“外掛”知識。
- 結合應用: 有時會將兩者結合,先對模型進行微調以適應特定領域,再使用RAG來獲取最新或詳細訊息。
L111 人工智慧概念
★★★★☆
金融業運用人工智慧 (AI) 指引
核心原則 (源自金管會)
台灣金融監督管理委員會針對金融業運用AI提出了六大核心原則,旨在引導業者在創新同時兼顧風險管理、公平性及消費者保護:
- 建立治理及問責機制: 業者應對其AI系統負責,建立內部治理架構,明確權責,並確保有足夠的知識與能力進行決策和監督。
- 重視公平性及以人為本: 避免演算法偏見造成的不公平對待,尊重法治與民主價值,並確保人類可控。
- 保護隱私及客戶權益: 尊重和保護消費者隱私,妥善管理客戶資料,並尊重客戶選擇權。
- 確保系統穩健與安全: 確保AI系統的穩定性、可靠性和安全性,防範風險。
- 落實透明與可解釋性: 確保AI系統運作具透明度,決策過程可被解釋,並適當揭露資訊。
- 促進永續發展: 運用AI應結合永續發展原則,如減少不平等、保護環境、關懷員工。
指引重點
金管會發布的指引進一步細化了這些原則,強調風險為本的方法,要求金融機構在AI生命週期各階段(規劃設計、資料蒐集、模型建立、部署監控)關注治理、公平性、隱私保護、安全穩健、透明解釋、永續等面向,並對第三方業者的監督管理提出要求。
L123 生成式AI導入評估規劃
★★★★☆
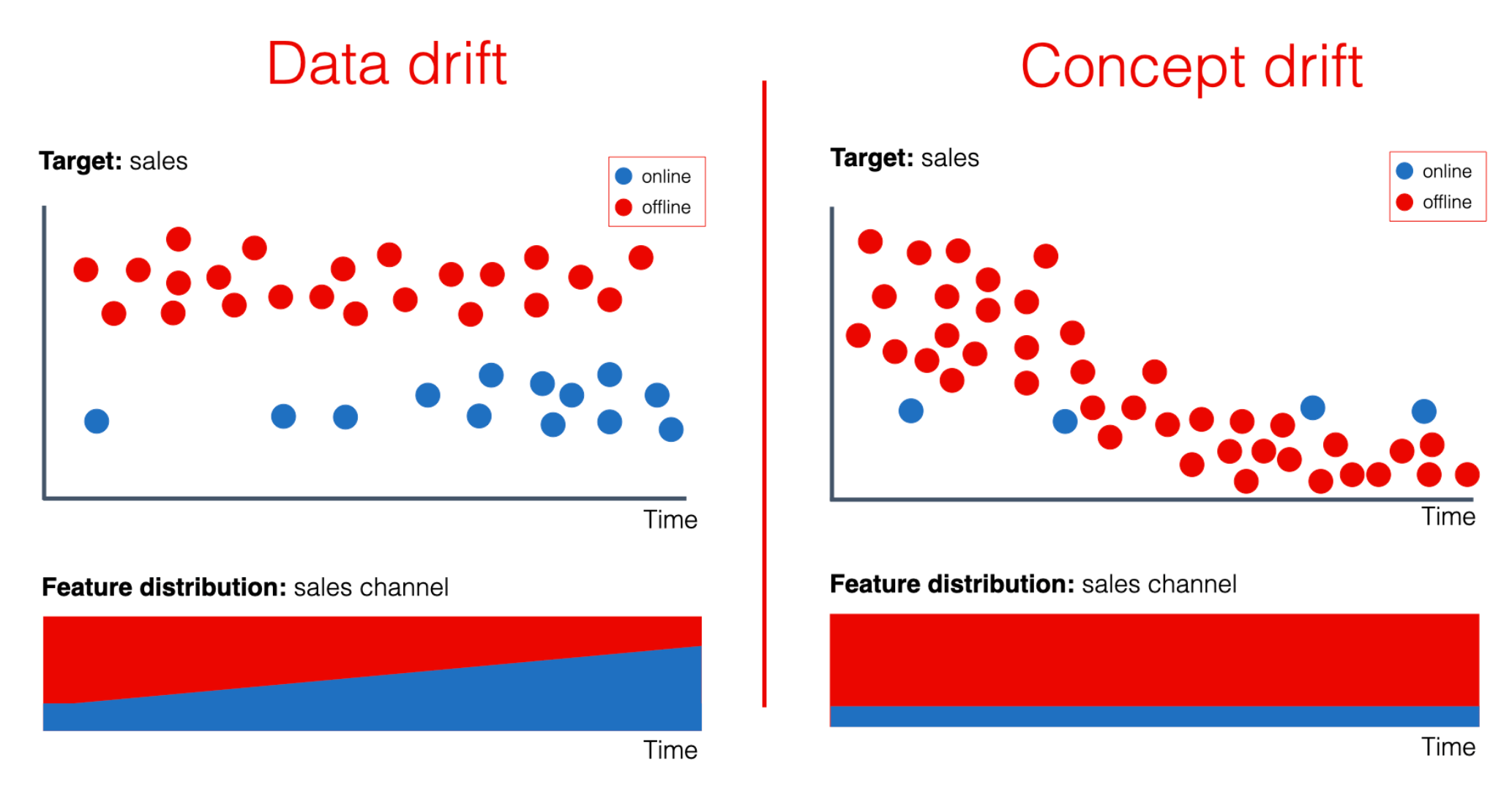
資料飄移 (Data Drift)
核心概念
資料飄移(也稱為概念飄移 Concept Drift,有細微差別但常混用)是指機器學習模型在部署到生產環境後,輸入數據的統計特性(如數據分佈、特徵之間的關係、目標變數與特徵的關係)隨時間發生了變化,導致這些數據與模型訓練時使用的數據不再一致。
由於模型是基於歷史數據學習的模式,當現實世界的模式發生改變時,模型的預測準確性就會下降。監控和處理資料飄移對於維持AI系統的長期性能至關重要。
由於模型是基於歷史數據學習的模式,當現實世界的模式發生改變時,模型的預測準確性就會下降。監控和處理資料飄移對於維持AI系統的長期性能至關重要。
L123 生成式AI導入評估規劃
★★★★★
提示工程 (Prompt Engineering) 相關概念
核心概念
提示工程是指設計和優化輸入給大型語言模型(LLM)等生成式AI的指令(Prompt),以有效引導模型產生期望的、高質量的輸出的藝術和科學。它涉及理解模型的能力、限制以及如何通過措辭、結構和上下文來影響其行為。
重要技術/概念
- 零樣本學習 (Zero-shot Learning): 不提供任何範例,僅通過指令要求模型完成任務。依賴模型內建的廣泛知識。
- 少樣本學習 (Few-shot Learning): 在提示中提供少量(通常1到幾個)相關範例,幫助模型理解任務格式和期望輸出。
- 思維鏈 (Chain-of-Thought, CoT): 引導模型展示其推理步驟,通常通過在提示中加入"Let's think step by step"或提供帶有推理過程的範例,以提高複雜問題(如數學、邏輯)的準確性。
- 提示洩漏 (Prompt Leakage / Data Leakage): 在提示或訓練數據中無意中包含了模型在實際應用中不應獲知的訊息(如測試集答案、未來數據),導致模型性能被高估。
- 提示注入 (Prompt Injection): 一種安全攻擊,攻擊者精心構造惡意提示,覆蓋或繞過原始指令,誘導模型執行非預期操作(如洩露敏感訊息、生成有害內容)。
提示優化
涉及迭代修改提示,使其更清晰、具體、包含足夠上下文,並利用特定技巧(如指定角色、格式、輸出要求)來獲得更好的模型輸出。
L122 生成式 AI 應用領域與工具使用
★★★☆☆
AI 工具 - 程式碼生成
功能
指利用AI技術自動生成程式碼,可以根據自然語言描述、註釋或現有代碼片段來產生新的代碼、完成代碼、除錯或優化。
常見工具
- GitHub Copilot: 由GitHub和OpenAI合作開發,作為IDE插件提供實時代碼建議和生成。
- OpenAI Codex: GPT模型的一個分支,專門訓練用於理解和生成程式碼,是Copilot的底層技術。
- Cursor: 一款整合了AI功能的代碼編輯器,提供代碼生成、問答、除錯等能力。
L122 生成式 AI 應用領域與工具使用
★★★☆☆
AI 工具 - 音樂生成
功能
指利用AI技術創作音樂,可以根據文本提示、風格指定或其他輸入自動生成旋律、和聲、伴奏甚至完整歌曲(包括人聲)。
代表工具
Suno AI: 一款流行的生成式AI音樂創作平台,使用者可以通過簡單的文字提示(描述風格、主題、歌詞等),快速生成包含人聲和伴奏的高品質原創歌曲。
L122 生成式 AI 應用領域與工具使用
★★★☆☆
TAIDE (臺灣智慧對話引擎)
核心概念
TAIDE (Taiwan AI Dialogue Engine) 是由臺灣數位發展部主導,結合產官學研力量共同開發的大型語言模型 (LLM)。
其目標是打造一個基於繁體中文、符合臺灣語言文化、價值觀和法規環境的對話式AI,專注於提供在地化的應用與服務,並強調可信任AI (Trustworthy AI) 的發展。
其目標是打造一個基於繁體中文、符合臺灣語言文化、價值觀和法規環境的對話式AI,專注於提供在地化的應用與服務,並強調可信任AI (Trustworthy AI) 的發展。
L121 No code / Low code 概念
★★★★★
No code / Low code 平台
核心概念
No code 和 Low code 平台旨在使用圖形化介面和預構建組件來簡化應用程式開發,減少或消除傳統編碼需求。
- No code:** 完全不需要編寫程式碼,主要面向非技術背景的使用者(如業務人員),透過拖放、配置等方式快速構建簡單應用或自動化流程。
- Low code:** 需要少量編碼來實現更複雜的邏輯或客製化功能,主要面向開發者或具有一定技術能力的用戶,提供更高的靈活性和擴展性。
優勢與限制 (考點)
- 優勢: 降低開發門檻、加速開發速度、降低成本、促進IT與業務協作、加速數位轉型。
- 限制: No code 平台的客製化能力和可擴展性通常有限;Low code 平台可能存在廠商鎖定 (Vendor Lock-in) 風險;兩者都可能面臨性能瓶頸(對於超大規模應用)、整合複雜度(與舊系統)及影子IT(未經IT部門管理的應用擴散)等問題。
應用
快速原型設計、內部工具開發、業務流程自動化、客戶關係管理 (CRM) 客製化、簡單App開發等。
L123 生成式AI導入評估規劃
★★★★★
生成式AI 的風險
主要風險類型
生成式AI在帶來機遇的同時,也伴隨著多重風險,需要謹慎管理:
- 內容真實性與準確性風險:
- 幻覺 (Hallucination): 生成看似合理但事實錯誤或完全虛構的資訊。
- 過時資訊: 模型基於舊數據生成內容,無法反映最新情況。
- 偏見與歧視風險:
- 放大偏見: 模型可能學習並放大訓練數據中存在的社會偏見(性別、種族等),產生歧視性內容。
- 安全與隱私風險:
- 數據洩漏: 可能在生成內容時無意中洩露訓練數據中的敏感訊息或個人隱私。
- 提示注入 (Prompt Injection): 惡意用戶可能透過特殊提示操控模型行為。
- 對抗性攻擊: 產生對抗樣本欺騙模型。
- 濫用風險:
- 深度偽造 (Deepfake): 生成逼真的虛假圖像、音頻或影片,用於詐騙、誹謗或散布虛假訊息。
- 惡意內容生成: 被用於生成仇恨言論、釣魚郵件、惡意軟體代碼等。
- 智慧財產權與版權風險:
- 侵權: 生成的內容可能侵犯現有的版權或商標權。
- 歸屬不明: AI生成內容的版權歸屬問題尚不明確。
- 倫理與社會風險:
- 責任歸屬: AI生成錯誤內容或造成損害時,責任難以界定。
- 過度依賴: 可能導致人類批判性思維能力下降。
- 就業衝擊: 自動化內容創作可能影響相關行業的就業。
風險管理
需要建立全面的風險管理框架,包括數據治理、模型驗證、內容審核、使用規範、透明度措施和應急預案。
L122 生成式 AI 應用領域與工具使用
★★★☆☆
GPT-4o
核心特性
GPT-4o ("o" for omni) 是 OpenAI 在 GPT-4 基礎上推出的新一代旗艦模型。其最顯著的特點是原生多模態 (natively multimodal) 能力:
- 能夠接收文本、音頻、圖像作為組合輸入,並生成文本、音頻、圖像的組合輸出。
- 顯著提高了處理速度,尤其是在語音交互方面,反應時間接近人類對話。
- 在視覺和音頻理解方面比現有模型表現更佳。
- 在文本處理能力(如多語言、推理)上達到 GPT-4 Turbo 級別,同時速度更快、API成本降低50%。
L113 機器學習概念
★★★☆☆
迴歸模型應用
核心概念
迴歸模型 (Regression Model) 是一類用於預測連續數值型輸出(目標變數)的監督式學習模型。它試圖建立一個或多個輸入特徵(自變數)與連續輸出變數之間的數學關係。
目標是找到一個函數,能夠最好地擬合數據點,並用於預測新的、未見過的輸入數據所對應的連續值。
目標是找到一個函數,能夠最好地擬合數據點,並用於預測新的、未見過的輸入數據所對應的連續值。
常見應用
- 預測: 房價預測、股票價格預測、銷售額預測、天氣溫度預測、預測飲料銷量(考點案例)。
- 關係分析: 分析不同變數之間的關係強度和方向(如廣告投入與銷售額的關係)。
L113 機器學習概念
★★★☆☆
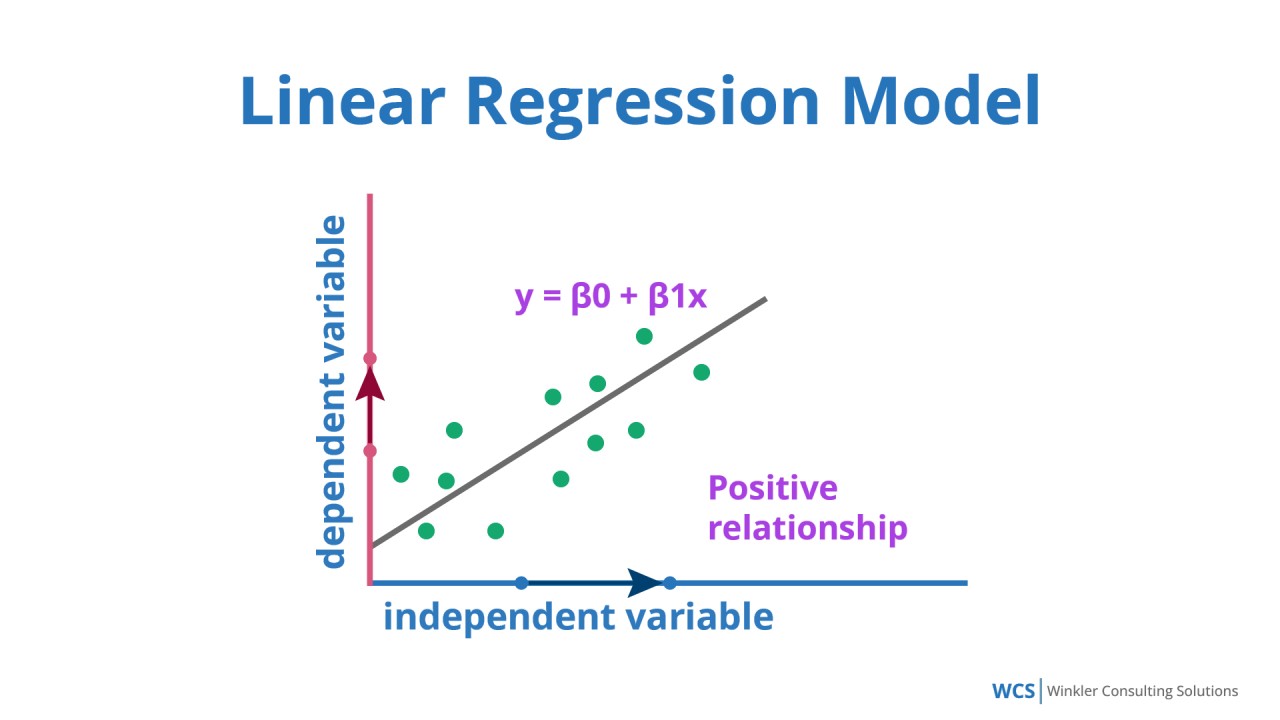
線性迴歸 (Linear Regression) 應用
核心概念
線性迴歸是最基礎的迴歸方法之一。它假設自變數(特徵)與因變數(目標值)之間存在線性關係,即可以用一條直線(或高維空間中的超平面)來擬合數據。
目標是找到最佳的迴歸係數(斜率和截距),使得模型預測值與實際值之間的誤差平方和最小。
目標是找到最佳的迴歸係數(斜率和截距),使得模型預測值與實際值之間的誤差平方和最小。
應用場景
適用於變數間關係大致呈線性的預測問題。例如:
- 根據房屋面積預測房價(假設面積越大,價格線性增長)。
- 根據廣告投入預測銷售額。
- 根據工齡預測薪資。
L122 生成式 AI 應用領域與工具使用
★★☆☆☆
圖像尺寸與DPI換算
核心概念
- 像素 (Pixel): 組成數位圖像的最小單位。圖像的像素尺寸表示其寬度和高度包含多少像素(例如 2048x2048 像素)。
- DPI (Dots Per Inch): 每英寸點數,用於描述打印輸出的解析度或精細度。DPI越高,打印出的圖像越清晰。
計算公式
打印尺寸(英寸) = 圖像像素尺寸 / DPI
例如,一張 2048x2048 像素的圖片,如果以 300 DPI 的解析度打印:
打印寬度 = 2048 像素 / 300 DPI ≈ 6.83 英寸
打印高度 = 2048 像素 / 300 DPI ≈ 6.83 英寸
因此,可以打印出約 6.83 x 6.83 英寸大小的清晰圖片。
例如,一張 2048x2048 像素的圖片,如果以 300 DPI 的解析度打印:
打印寬度 = 2048 像素 / 300 DPI ≈ 6.83 英寸
打印高度 = 2048 像素 / 300 DPI ≈ 6.83 英寸
因此,可以打印出約 6.83 x 6.83 英寸大小的清晰圖片。
L122 生成式 AI 應用領域與工具使用
★★★☆☆
AI工具選擇 - 補習班應用
情境分析
需求: 補習班需要一個AI平台來進行學生評鑑和撰寫評語。這本質上是一個文本生成 (Text Generation) 和摘要 (Summarization) 的任務,可能需要結合學生的表現數據(如成績、出勤、課堂參與)。
工具選擇
- 核心AI引擎: ChatGPT 或其背後的 OpenAI API(如GPT-4, GPT-4o)是強大的選擇,它們擅長理解上下文並生成連貫、自然的評語文本。
- 數據輸入/管理: 需要一個方式來輸入學生的評鑑數據(可能是結構化數據)。表單管理工具(如 Google Forms, Microsoft Forms 或客製化表單)可以收集這些數據。
- 整合方式: 可能需要將表單數據匯出,整理後作為提示 (Prompt) 的一部分輸入給 ChatGPT/API,或者通過API將表單數據直接傳遞給AI模型進行處理。
L114 鑑別式 AI 與生成式 AI 概念
★★★★☆
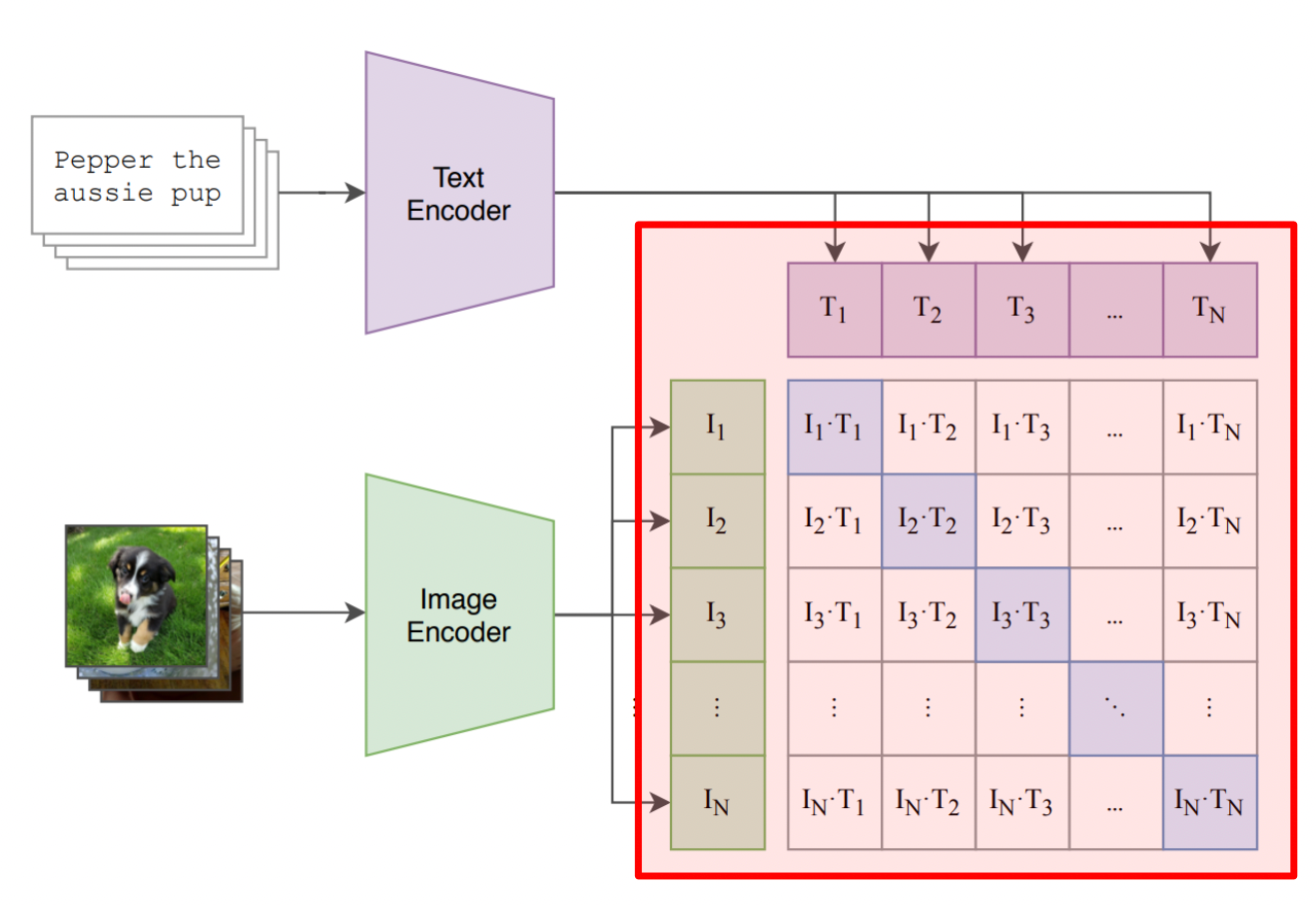
CLIP (Contrastive Language–Image Pre-training) 模型原理
核心概念
CLIP 是由 OpenAI 開發的一種多模態 (multi-modal) 模型,能夠同時理解圖像和自然語言。
其核心原理是通過對比學習 (Contrastive Learning) 的方式,在大規模圖像-文本配對數據上進行預訓練。
訓練過程中,CLIP 學習將語義相關的圖像和文本映射到同一個共享的嵌入空間 (embedding space) 中相近的位置,而將不相關的推遠。
這使得模型能夠衡量圖像和文本描述之間的相似度,從而實現強大的零樣本 (zero-shot) 圖像分類、圖像文本檢索等跨模態任務能力。
其核心原理是通過對比學習 (Contrastive Learning) 的方式,在大規模圖像-文本配對數據上進行預訓練。
訓練過程中,CLIP 學習將語義相關的圖像和文本映射到同一個共享的嵌入空間 (embedding space) 中相近的位置,而將不相關的推遠。
這使得模型能夠衡量圖像和文本描述之間的相似度,從而實現強大的零樣本 (zero-shot) 圖像分類、圖像文本檢索等跨模態任務能力。
L123 生成式AI導入評估規劃
★★★☆☆
對抗性實驗 (Adversarial Experiment)
核心概念
對抗性實驗是一種用於測試和評估 AI 模型、系統或演算法穩健性 (Robustness) 和安全性的技術。
其核心思想是故意設計出具有挑戰性或欺騙性的輸入數據(稱為對抗樣本, Adversarial Examples)或情境,這些輸入對於人類來說可能差異微小或無關緊要,但卻容易導致AI系統做出錯誤的預測或判斷。
通過觀察系統在這些“蓄意挑戰”下的表現,可以發現其潛在的弱點、錯誤模式、偏見或脆弱性,從而進行改進。
其核心思想是故意設計出具有挑戰性或欺騙性的輸入數據(稱為對抗樣本, Adversarial Examples)或情境,這些輸入對於人類來說可能差異微小或無關緊要,但卻容易導致AI系統做出錯誤的預測或判斷。
通過觀察系統在這些“蓄意挑戰”下的表現,可以發現其潛在的弱點、錯誤模式、偏見或脆弱性,從而進行改進。
應用
常用於測試圖像識別模型的抗干擾能力、自然語言模型的語義理解魯棒性、以及評估AI系統在安全關鍵領域(如自動駕駛、醫療診斷)的可靠性。
L123 生成式AI導入評估規劃
★★☆☆☆
延遲性實驗 (Latency Testing)
核心概念
延遲性實驗主要用於測量和分析AI系統、網路應用或任何計算系統在處理請求或執行任務時所花費的時間,即延遲 (Latency) 或響應時間 (Response Time)。
目的是評估系統的性能,找出潛在的瓶頸,分析延遲對使用者體驗 (UX) 的影響,並優化系統以提高反應速度。
測試通常涉及模擬不同負載或條件下的請求,並記錄從發出請求到收到完整響應所需的時間。
目的是評估系統的性能,找出潛在的瓶頸,分析延遲對使用者體驗 (UX) 的影響,並優化系統以提高反應速度。
測試通常涉及模擬不同負載或條件下的請求,並記錄從發出請求到收到完整響應所需的時間。
L111 人工智慧概念
★★★☆☆
AI 代理人 (AI Agent)
核心概念
AI 代理人是指任何能夠感知其環境(通過感測器),自主決策,並採取行動(通過執行器)以達成特定目標的AI系統。
其核心功能是圍繞著目標導向的行為循環:感知 → 思考/決策 → 行動。
AI 代理人的設計目的是完成被賦予的任務或實現目標,例如贏得遊戲、導航、回答問題、控制機器等,而不是進行科學或工程上的“原創性發明”。雖然其決策過程可能很複雜或創新,但其根本目標是應用現有能力解決問題,而非創造全新的基礎技術。因此,發明新技術不屬於AI代理人的核心功能。
其核心功能是圍繞著目標導向的行為循環:感知 → 思考/決策 → 行動。
AI 代理人的設計目的是完成被賦予的任務或實現目標,例如贏得遊戲、導航、回答問題、控制機器等,而不是進行科學或工程上的“原創性發明”。雖然其決策過程可能很複雜或創新,但其根本目標是應用現有能力解決問題,而非創造全新的基礎技術。因此,發明新技術不屬於AI代理人的核心功能。
L113 機器學習概念
★★★★☆
泛化能力 (Generalization)
核心概念
泛化能力是指機器學習模型在訓練完成後,能夠很好地適應從未見過的新數據或新環境的能力。一個具有良好泛化能力的模型,不僅能在訓練數據上表現出色,更重要的是能在實際應用中對新的、未知的輸入做出準確的預測或判斷。
泛化能力差通常表現為過擬合(Overfitting),即模型過度學習了訓練數據的細節和噪聲,而無法捕捉到數據背後的一般規律。
泛化能力差通常表現為過擬合(Overfitting),即模型過度學習了訓練數據的細節和噪聲,而無法捕捉到數據背後的一般規律。
與其他能力的區別
- 自我學習 (Self-learning): 側重於模型從數據中自主學習模式的能力。
- 推理能力 (Reasoning): 側重於模型基於已有知識進行邏輯推斷和解決問題的能力。
沒有找到符合條件的重點。
↑