📚 HTML 考題小舖
📖 iPAS AI應用規劃師-初級能力鑑定 精選模擬試題/重點整理(免費試閱)
📖 iPAS AI應用規劃師-中級能力鑑定 精選模擬試題/重點整理(免費試閱)
📖 2025年最新版 Azure AI900 微軟中文版題庫【免費試閱】
📖 2025年最新版微軟證照題庫系列【AZ-900】【AI-102】【AI-900】【DP-900】【PL-900】等
初級 AI應用規劃師 經典回顧卷001
2025/03/22 (第1場考試重點整理)
評鑑主題 (點擊篩選)
L111 人工智慧概念
★★★★★
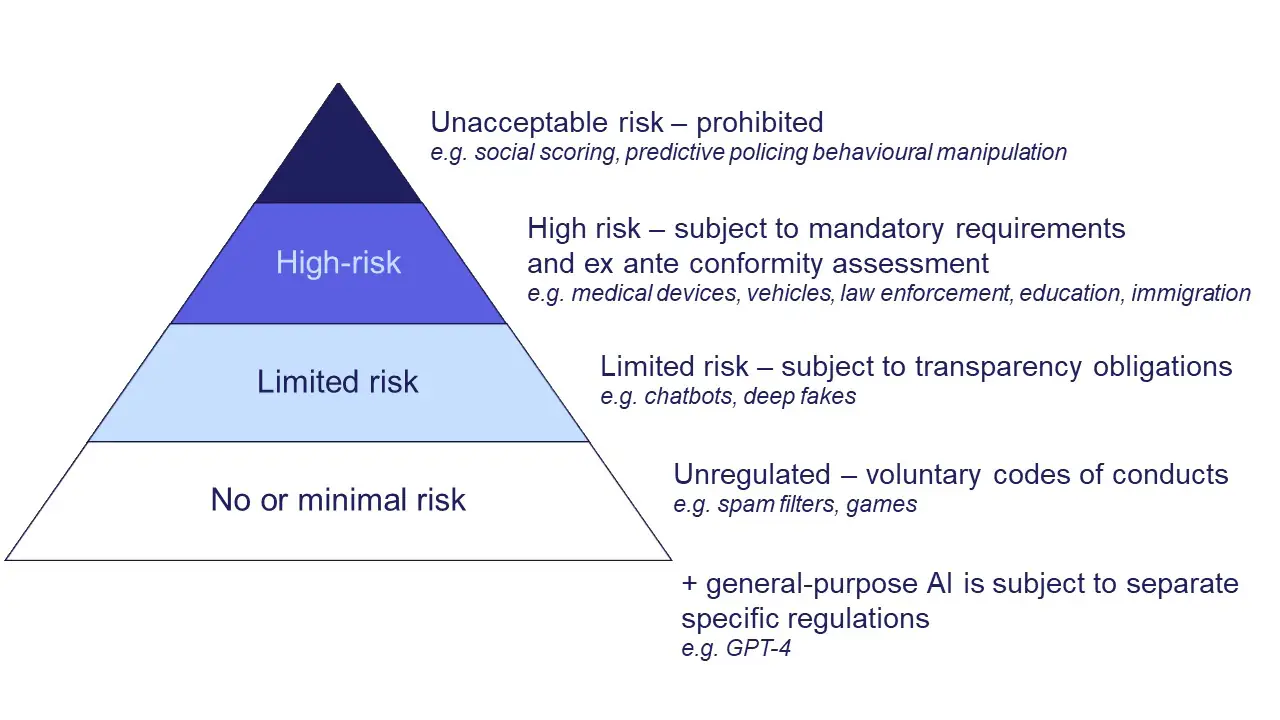
歐盟 AI Act 四級風險等級與範例
風險分級
AI Act 將 AI 系統風險分為四級:
- 不可接受風險(例如社交評分、操縱行為的系統),此類 AI 應用明文禁止。
- 高風險(如醫療診斷、無人車、自動駕駛、招聘系統),允許使用但需符合嚴格監管要求(風險評估、記錄保存、透明度等)。
- 有限風險(如聊天機器人、深偽內容),須遵守透明度義務(系統須告知用戶其為 AI、標示 AI 生成內容)。
- 最低風險(如垃圾郵件過濾器、遊戲 NPC),基本不受額外限制。
風險等級表
| 風險等級 | 說明 | 範例 |
|---|---|---|
| 不可接受風險 (Unacceptable risk) |
完全禁止 |
|
| 高風險 (High risk) |
需符合強制性要求與事前合規評估(ex ante conformity assessment) |
|
| 有限風險 (Limited risk) |
須遵守透明義務(transparency obligations) |
|
| 無或極低風險 (No or minimal risk) |
未受監管,依循自願性行為準則(voluntary codes of conducts) |
|
L111 人工智慧概念
★★★★☆
負責任 AI 的定義與責任歸屬
核心概念
負責任人工智慧指以道德、可靠和透明的方式來設計、開發與部署 AI 系統,確保 AI 帶來的影響符合人類價值和法規要求。例如避免偏見決策、確保決策可解釋。
責任歸屬方面,AI 系統的行為由其開發者和部署者承擔責任——也就是由人類(組織)對 AI 結果負責,而AI 系統本身無法對其行為負責。考題可能詢問誰應對 AI 行為負責,正確答案通常是開發者/提供者(而非使用者、政府或 AI 自身)。
L113 機器學習概念
★★★★☆
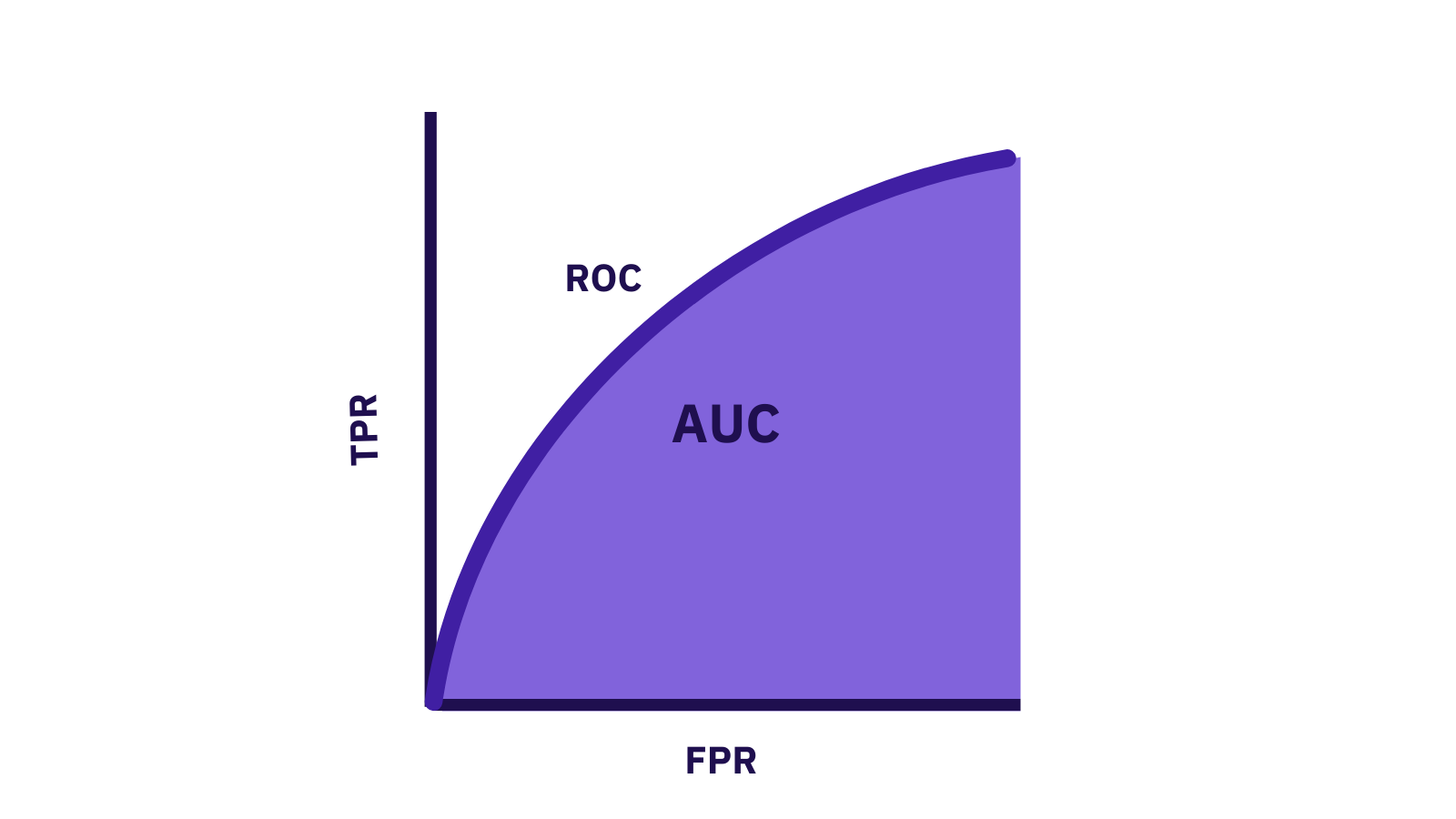
ROC 曲線與 AUC 的意義與應用
核心概念
ROC 曲線(接收者操作特徵曲線)描繪分類模型在不同判斷閾值下的真陽率 (TPR) 對假陽率 (FPR) 的關係,用來評估模型區分正反兩類的能力。AUC 是 ROC 曲線下的面積,介於 0.5 到 1 之間,數值愈大代表模型整體判別性能愈佳。 AUC 可作為比較不同模型的指標且不受特定閾值影響。
應用說明
在應用上,ROC/AUC 常用於二元分類(如疾病檢測)的模型評估,協助選擇最佳閾值:若希望減少誤報,可提高閾值以提升精確率但可能降低召回率;反之為提高召回率可降低閾值接受較多誤報。ROC 曲線提供這種權衡的視覺化工具,而 AUC 則量化模型的綜合表現。
L112 資料處理與分析概念
★★★☆☆
資料類型與資料處理要點
資料型態
資料型態可分為:
- 數值型(連續型或離散型)
- 類別型(名目/順序)
- 文字
- 圖像等
資料處理流程
資料處理流程包含:資料收集、資料清理、資料分析、資料視覺化。
其中異常值(outlier)處理很重要:異常值是遠離其他觀測值的資料點,可能因錯誤產生。處理方式包括檢查原因、在分析時排除或以適當值取代,以降低異常值對結果的影響。
集中趨勢
描述集中趨勢(資料的代表性值)時常使用:平均數、中位數(對極端值較不敏感)、眾數。當資料偏態嚴重或含有異常值時,中位數比平均數更能代表典型水準。
圖表應用
在圖表應用方面,不同圖表適合不同資料:
- 長條圖:比較類別資料頻率
- 折線圖:展示時間趨勢
- 散佈圖:檢視兩變數關係
- 直方圖或盒狀圖:檢查數據分佈及異常值
L113 機器學習概念
★★★★★
機器學習基本概念與四種學習方式
核心概念
機器學習是讓電腦從資料中學習模式以進行預測或決策的技術。常見的四種學習方式包括:
- 監督式學習:利用有標籤資料訓練模型,學習輸入到正確輸出(標籤)的映射。應用如分類(將郵件分類為垃圾或非垃圾)與迴歸(預測房價)。
- 非監督式學習:資料沒有標籤,模型需自行發現資料內在結構或分佈。例如分群(如 K-means 將客戶分群)或降維(PCA 將高維資料投影到較低維度)。
- 半監督式學習:同時利用少量有標籤資料和大量無標籤資料訓練模型。透過未標註資料的輔助,可在標籤取得不易時提升模型表現,例如只有部分影像有標籤時仍利用大量無標籤影像來訓練模型。
- 強化學習:代理(agent)透過與環境互動並根據獎懲回饋學習策略。在試錯過程中,不斷調整行動以最大化長期獎勵。典型案例如遊戲 AI(AlphaGo 與自身對弈學習圍棋策略)或自駕車透過模擬學習駕駛決策。強化學習不需要範例輸出,而是以獎勵訊號引導模型行為。
L113 機器學習概念
★★★★★
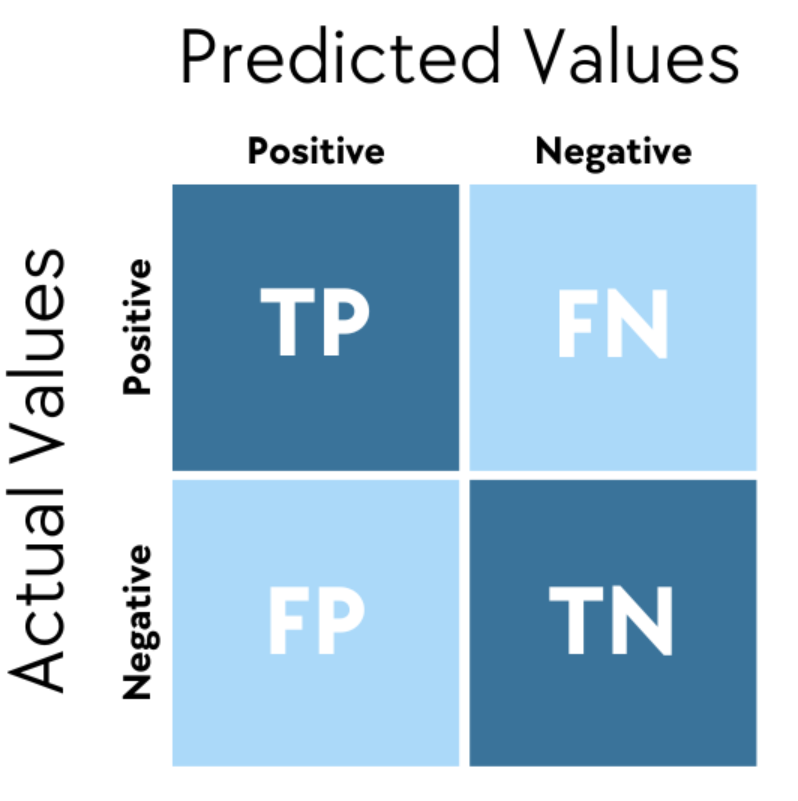
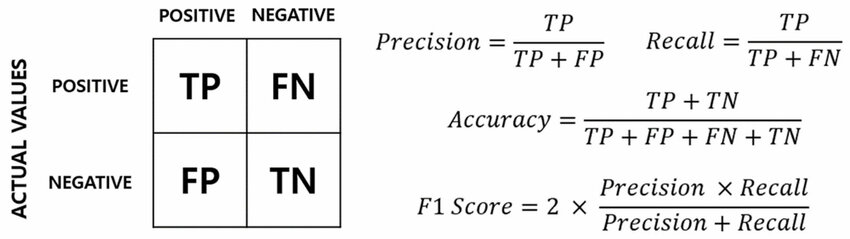
混淆矩陣與模型效能指標
核心概念
混淆矩陣 (Confusion Matrix) 是評估分類模型表現的工具,以矩陣呈現預測與實際的組合結果。矩陣四格包括:真正例 (TP)、假正例 (FP)、假負例 (FN)、真負例 (TN)。由此衍生多種效能指標:
- 精確率 (Precision) = TP/(TP+FP),表示模型預測為正的案例中有多少比例實際為正(預測精準度)。精確率高代表誤報少。
- 召回率 (Recall) = TP/(TP+FN),表示實際為正的案例中有多少比例被模型找出(敏感度)。召回率高代表漏判少。
- F1 值 (F1-score) = 精確率與召回率的調和平均,用於衡量精確率和召回率的整體表現。當需要平衡兩類錯誤時,F1 是較佳指標。
L114 鑑別式 AI 與生成式 AI 概念
★★★★☆
深度學習、生成式 AI 與鑑別式 AI 的定義與比較
定義
深度學習 (Deep Learning) 是機器學習的子領域,使用多層神經網路從大量資料中自動學習特徵和模式,實現端到端的預測。深度學習支撐了許多 AI 應用(如圖像識別、語音辨識)並帶來突破。
生成式 AI (Generative AI) 指能生成新內容的模型,透過學習資料的機率分佈來產生類似樣本(如文本、圖像、音訊)。例子包括 GPT 系列大型語言模型(生成對話、文章)、圖像擴散模型(生成圖像)等,可創造出原訓練集中沒有的新數據。
鑑別式 AI (Discriminative AI) 指辨別輸入所屬類別的模型,直接學習輸入到目標的映射,例如圖片分類模型判斷「貓或狗」、垃圾郵件檢測模型判斷「是否垃圾信」。鑑別式模型關注於區分已有的類別,無法生成新內容。
生成式 AI (Generative AI) 指能生成新內容的模型,透過學習資料的機率分佈來產生類似樣本(如文本、圖像、音訊)。例子包括 GPT 系列大型語言模型(生成對話、文章)、圖像擴散模型(生成圖像)等,可創造出原訓練集中沒有的新數據。
鑑別式 AI (Discriminative AI) 指辨別輸入所屬類別的模型,直接學習輸入到目標的映射,例如圖片分類模型判斷「貓或狗」、垃圾郵件檢測模型判斷「是否垃圾信」。鑑別式模型關注於區分已有的類別,無法生成新內容。
比較
比較:生成式模型能產生數據(可用於資料增強或內容創作),但訓練難度較高且生成結果需防範失真或不當內容;鑑別式模型在分類任務上更直接高效。深度學習模型既可用於生成式(如 GAN 生成人臉)也可用於鑑別式(如 CNN 分類影像),深度學習提供的強大表達能力讓兩類 AI 都取得長足發展。理解區別重點:生成式側重「生成新資料」,鑑別式側重「區分類別」。
L113 機器學習概念
★★★★☆
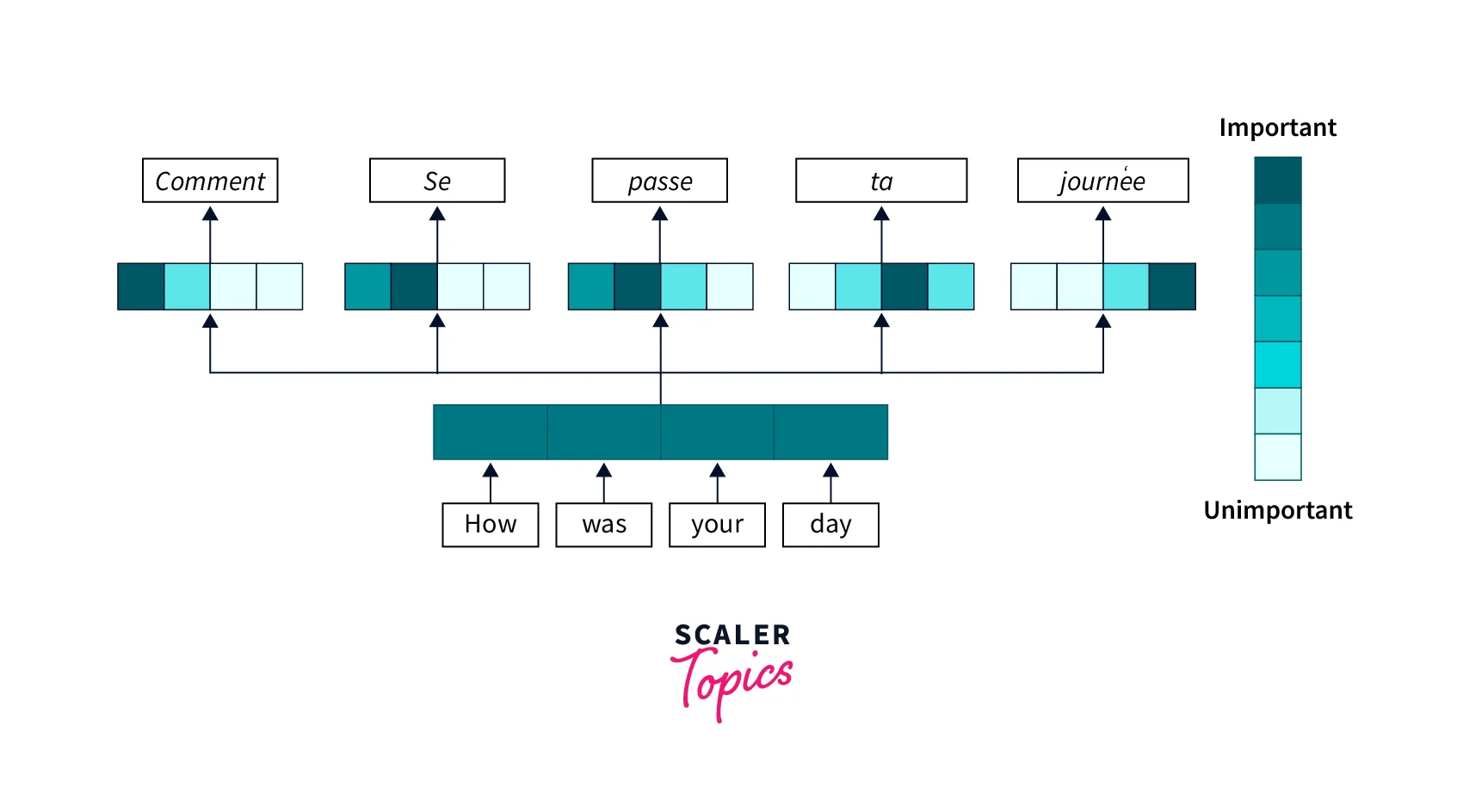
Transformer 核心技術:注意力機制
核心概念
注意力機制 (Attention) 是 Transformer 模型的核心技術,使模型在處理序列資料時能動態關注最相關的部分。其原理是:對於輸入序列中的每個元素(如句子中的單詞),模型計算它與序列中其他元素之間的關聯權重,從而在生成該位置的表示時加權考量其它重要元素。自注意力機制允許模型在同一序列中長距離依賴,例如翻譯時一個單詞可以參考句子中遠處與之對應的詞。Transformer 採用多頭注意力 (Multi-head Attention) 從不同子空間抽取關聯特徵,並行處理提升效率。
優點
優點:注意力使模型能靈活聚焦關鍵訊息(如翻譯對齊、摘要抓重點),捕捉長程關係並忽略無關訊息。這使 Transformer 在翻譯、問答等任務上效果遠勝傳統 RNN。掌握注意力機制有助理解 Transformer 如何有效處理長序列資訊,這是現代 NLP 模型的基石之一。
L113 機器學習概念
★★★★★
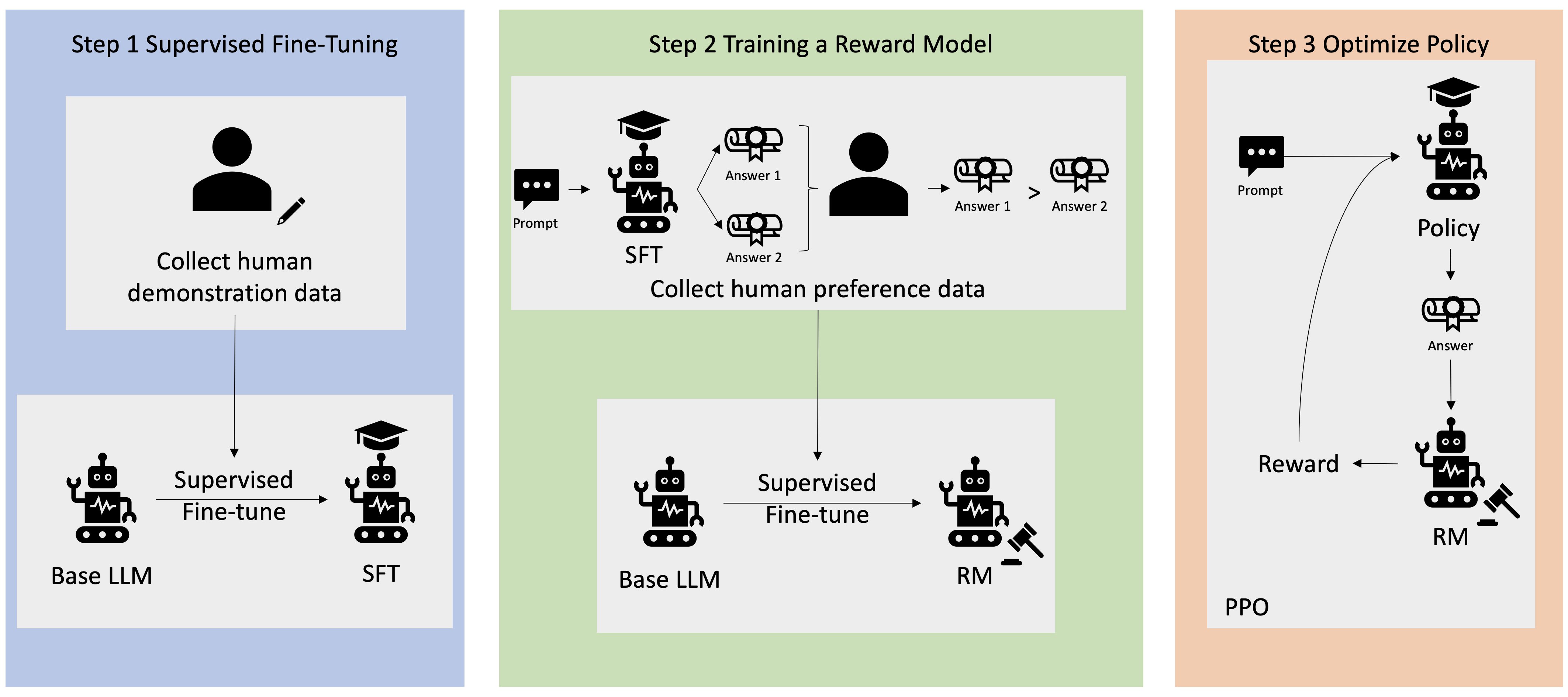
RLHF (Reinforcement Learning from Human Feedback, 人類回饋強化學習) 的步驟流程
核心步驟
RLHF 透過人類反饋來優化 AI 模型,以下是正確的實現步驟:
- 提示示範階段:由人類專家提供示範資料(如理想回答示例),先對預訓練模型進行監督式微調,讓模型學會基本的回答模式。
- 獎勵模型訓練:收集模型輸出的不同回應,讓人類對其品質進行排序或評分,據此訓練一個獎勵模型來評估回答的好壞(建立人類偏好評分標準)。
- 強化學習調整:使用強化學習演算法(如 PPO)讓模型反覆生成回答並由獎勵模型打分,根據得分調整模型參數,優化模型使其產生更符合人類偏好的回應。
- 模型部署應用:將經上述步驟優化的模型投入實際應用,持續監控效果,必要時融入新的人類反饋再次調校。
L112 資料處理與分析概念
★★★☆☆
大型語言模型 (LLM) 與自然語言處理 (NLP) 概念與常見誤解
核心概念
自然語言處理(NLP)是讓電腦理解和產生人類語言的技術領域,包括機器翻譯、問答系統、情感分析、對話等應用。大型語言模型(LLM)是在海量文本上預訓練的巨型模型,能執行各種 NLP 任務(如生成回答、摘要文章)。ChatGPT 即為 LLM 範例。LLM 通常基於 Transformer 架構,具備理解上下文與產生連貫語句的能力。
常見誤解
常見誤解:考題可能給出幾個技術名詞讓考生辨識何者與 NLP 無關。例如「影像辨識」不屬於 NLP 任務(那是計算機視覺領域)。另一常見誤解是混淆縮寫:NLP 是 Natural Language Processing(自然語言處理),與程式語言無關;LLM 是 Large Language Model(大型語言模型),指模型規模龐大而非特定語言。總之,要理解 NLP 涵蓋一切語言文本相關 AI 應用,而 LLM 是其中重要的模型類型。
L111 人工智慧概念
★★★★☆
應用場景題型示例 (無人車、智慧客服、健康評估)
場景分析
考試常以情境題考察對 AI 應用的理解,典型場景包括:
- 無人車(自動駕駛):屬於高風險 AI 應用,因直接關係人身安全。無人車運用了電腦視覺(環境感知)、感測器融合與強化學習決策等技術來自主駕駛,此領域特別強調模型的安全可靠,以及意外責任的劃分(道德與法律挑戰)。
- 智慧客服(聊天機器人客服):應用了自然語言處理和 LLM 技術自動回應客戶提問,一般屬有限風險(需要告知用戶正在與 AI 交談,以符合透明度要求)。重點在確保回覆的正確性與適切性,考題可能詢問此場景適合用哪些 AI 技術(如意圖辨識、知識庫檢索)或如何提升客服 AI 的表現(如結合人工協助處理複雜問題)。
- 健康評估(醫療風險預測):屬於高風險 AI 應用,因決策影響生命安全。通常要求模型具備極高的召回率(降低漏診概率)並經過嚴格驗證。該場景需要確保 AI 符合醫療法規與倫理,例如保護患者隱私和提供結果解釋。考題可能涉及:在此情境下應優先考慮哪項性能指標(如召回率優於精確率),或該應用在 AI Act 中屬於何種風險等級(高風險,需嚴格監管)。
L113 機器學習概念
★★★★☆
正則化 (Regularization)
核心概念
正則化是在模型訓練中加入額外約束或懲罰項,以防止模型過於複雜而發生過擬合(即在訓練資料上表現極佳但無法泛化到新資料)。常見正則化技術有:L2 正則化(在損失函數加入權重平方懲罰,促使參數值偏小)、L1 正則化(加入權重絕對值懲罰,促進模型產生稀疏權重)、Dropout(隨機丟棄部分神經元降低過度適應)、以及提前停止訓練 (Early Stopping,根據驗證集表現適時停止)。透過正則化,可降低模型複雜度並提升對未知資料的泛化能力。如果考題問到「如何減少過擬合」,正則化是標準對策之一。
L112 資料處理與分析概念
★★★☆☆
特徵提取 (Feature Extraction)
核心概念
特徵提取是將原始資料轉換為可供模型利用的關鍵變數的過程。也就是從原始數據中抽取出最能代表問題特性的指標,以提升模型學習效率與效果。良好的特徵提取可大幅提高模型性能:
- 結構化資料:可透過創造新變數(例如從日期萃取「星期幾」、「月份」等特徵)、對數值轉換(如取對數緩解偏態)等方式提取信息。
- 非結構化資料:對圖像,可使用卷積神經網路自動學習視覺特徵,或傳統方法提取顏色、形狀、紋理等;對聲音,提取 MFCC 等音頻特徵;對文本,使用詞袋模型(統計詞頻)或詞向量(如 Word2Vec 將詞語轉為向量)來表徵語意。
L122 生成式 AI 應用領域與工具使用
★★★☆☆
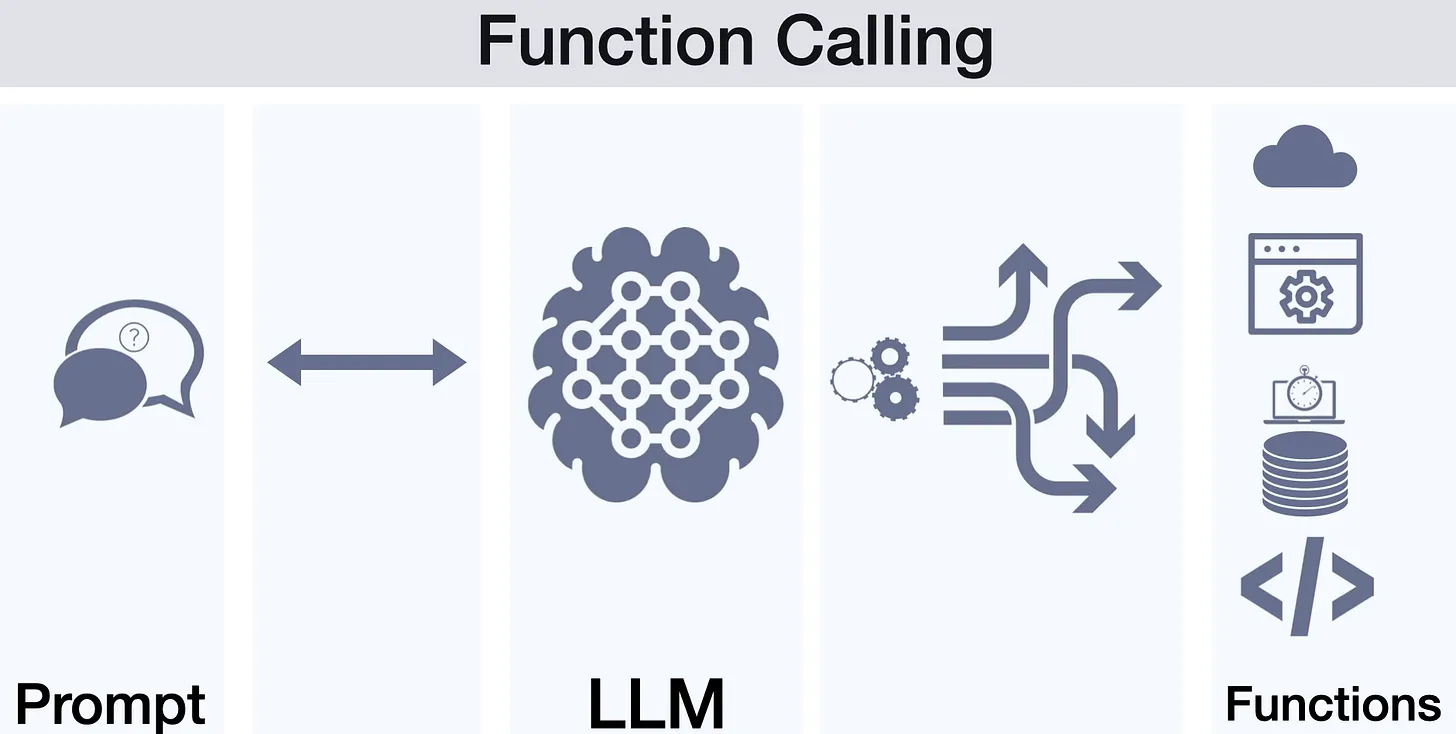
Function Calling 功能
核心概念
Function Calling 是大型語言模型(如 ChatGPT)中新推出的擴充功能,允許模型在對話中調用外部函式來完成任務。實現方式是:開發者預先定義可用函式介面,當用戶詢問的內容需要藉助工具時,模型輸出特定格式(如 JSON)的函式名稱與參數,由系統執行該函式並將結果返回模型。
應用舉例
應用舉例:用戶問「今天台北天氣如何」,模型可呼叫天氣 API 獲取實時資訊;或詢問數學計算,模型呼叫計算函式得到準確結果。透過 Function Calling,AI 不再侷限於文字回答,還能執行查詢、計算等操作,增強了回覆的準確性和功能性。考題若問此功能是什麼,回答為「讓 LLM 能夠透過呼叫程式函式來查得答案或執行操作」即可。
L122 生成式 AI 應用領域與工具使用
★★★☆☆
Canvas 引入功能
核心概念
Canvas 是 ChatGPT 平台近期加入的新介面,讓 AI 不再侷限於純文字對話,而具備圖文並茂的協作能力。Canvas 提供左右分屏視圖:左側是對話區,右側是畫布區,可用於和 AI 共同編輯文件或程式碼。
核心功能
核心功能:Canvas 支援執行 Python 程式碼並即時顯示結果(文字輸出或圖表),方便用戶邊對話邊運行代碼;提供內嵌評論功能,AI 可在文件中直接標註建議修改;也支援 AI 生成圖像等多媒體內容。在 Canvas 模式下,ChatGPT 成為一個集成編輯器、執行環境與智能助手於一體的工具。
Canvas 的引入使 ChatGPT 從單純聊天提升為創作協作平台,人機互動更為緊密高效(例如可共同撰寫報告、即時調整程式碼並查看結果)。考題若問 Canvas 帶來哪些新功能,可回答:「允許 ChatGPT 直接執行程式碼、生成圖表/圖像,並與使用者在畫布上共同編輯內容」等。
Canvas 的引入使 ChatGPT 從單純聊天提升為創作協作平台,人機互動更為緊密高效(例如可共同撰寫報告、即時調整程式碼並查看結果)。考題若問 Canvas 帶來哪些新功能,可回答:「允許 ChatGPT 直接執行程式碼、生成圖表/圖像,並與使用者在畫布上共同編輯內容」等。
L111 人工智慧概念
★★★☆☆
L11101 人工智慧 (Artificial Intelligence, AI) 的定義
定義
人工智慧是讓電腦系統能執行通常需要人類智慧才能完成的任務之理論與技術,例如視覺感知、語音辨識、決策以及語言翻譯等能力。
L111 人工智慧概念
★★★☆☆
L11101 人工智慧 (AI) 的分類
分類方式
AI可以依目標與能力範圍分為弱人工智慧(Narrow AI)和強人工智慧(General AI)。弱AI專注於單一領域的特定任務(例如只會下棋的程式),強AI則具有類似人類的通用智慧,可在不同領域執行各種任務。目前大多數AI屬於弱AI,真正的強AI尚未出現。
L111 人工智慧概念
★★★★☆
L11102 AI治理概念
核心概念
為確保人工智慧技術的負責任使用,各國陸續提出AI治理(AI Governance)框架與規範。這些框架強調倫理原則(如公平、透明、問責),並制定指南以降低AI應用風險。例如,歐盟推動《AI法案》草案採用風險分級的監管方式,台灣數位發展部發布《公部門人工智慧應用參考手冊》,金融監管機關亦制定《金融業運用AI指引》等指導原則,確保AI系統符合隱私與道德標準。
L111 人工智慧概念
★★★★★
L11102 AI風險等級分類 (歐盟)
風險分級
歐盟將AI系統依風險高低劃分為四個等級,並對不同等級設定相應的監管要求如下表:
| 風險等級 | 監管要求 | 範例 |
|---|---|---|
| 不可接受風險 | 嚴禁使用 | 社會信用評分系統、大眾即時生物辨識監控 |
| 高風險 | 嚴格管制(需符合嚴格法規、事前審查等) | 醫療診斷AI、銀行貸款信用評分AI、自動駕駛系統 |
| 有限風險 | 有限制使用(需履行特定透明度義務) | 聊天機器人(需告知為AI)、AI生成影像/Deepfake內容 |
| 最低風險 | 自由使用(一般情況無額外限制) | AI遊戲對手、垃圾郵件過濾器 |
L112 資料處理與分析概念
★★★☆☆
L11201 資料基本概念與來源
核心概念
大數據(Big Data)通常具有巨量 (Volume)、多樣 (Variety)、高速 (Velocity) 等特性,資料來源包括感測器、網路平台、企業交易紀錄等。資料依型態可区分为結構化與非結構化,例如數值資料、文字、圖像、音訊等。

L112 資料處理與分析概念
★★★☆☆
L11202 資料整理與分析流程
流程步驟
資料從收集到分析一般經歷一系列步驟,包括資料收集、資料清理、資料分析,以及結果呈現與視覺化等。透過這些流程將原始資料轉化為有意義的資訊,以支援決策制定。
L112 資料處理與分析概念
★★★★☆
L11203 資料隱私與安全
核心概念
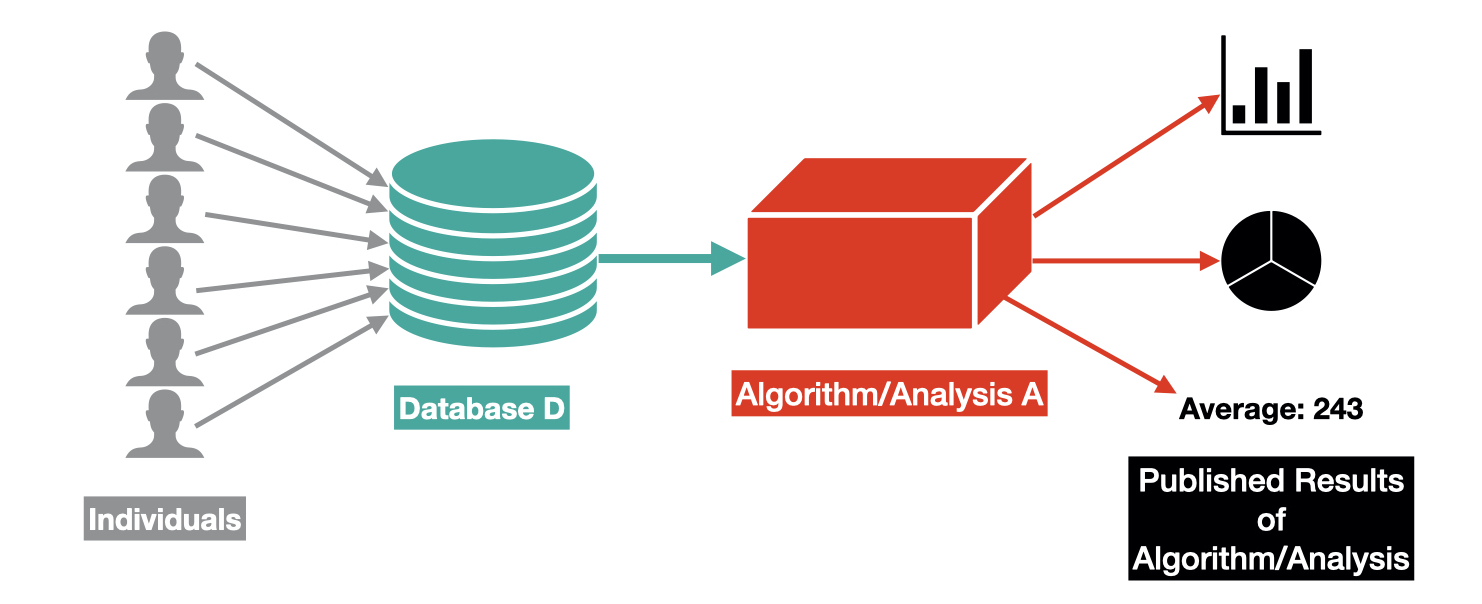
在AI專案中必須保護資料隱私與安全,避免洩露敏感個人資訊。常見作法是對個人識別資訊(Personally Identifiable Information, PII)進行去識別化處理(例如移除姓名、身分證號等直接識別資訊),但僅移除PII可能不足以防止重識別風險。相比之下,差分隱私(Differential Privacy, DP)透過在統計結果中加入隨機雜訊,以確保分析結果不會暴露任何單一個體的資料,提供更嚴格的隱私保護。除此之外,還需搭配權限控管、資料加密等安全措施來全面保障資料安全。
L113 機器學習概念
★★★☆☆
L11301 機器學習 (Machine Learning, ML) 基本原理
原理說明
機器學習讓電腦透過資料自我學習模式來執行任務,而不需要人工寫死規則。模型在輸入大量已知資料後,透過演算法自動調整內部參數以提取資料中的隱含規則,從而對新資料做出預測或決策。
L113 機器學習概念
★★★★☆
L11302 常見的機器學習模型 (學習方式分類)
分類
機器學習可依訓練資料的標記狀況分為幾種類型:
- 監督式學習(Supervised Learning):利用帶有正確答案的標記資料訓練模型,進行分類或迴歸預測。
- 非監督式學習(Unsupervised Learning):從未標記資料中發現內在結構,例如將資料自動分群。
- 半監督式學習(Semi-supervised Learning):結合少量標記資料與大量未標記資料,以提升模型的表現。
- 強化式學習(Reinforcement Learning):讓智能體在環境中透過試誤獲取獎勵,從而學習最佳策略。
L114 鑑別式 AI 與生成式 AI 概念
★★★★☆
L11401 鑑別式 AI 與 生成式 AI 的基本原理
原理比較
鑑別式 AI(Discriminative AI)著重於從輸入資料中辨識模式並做出判斷,例如對圖片進行分類或對數據進行預測。
生成式 AI(Generative AI)則學習資料的分佈以產生新內容,例如生成文本、圖像或聲音。
簡而言之,鑑別式模型側重於區分或識別(例如辨識圖片中的物件是貓或狗),而生成式模型則致力於創造數據(例如根據訓練語料自動寫出一段文字)。
L114 鑑別式 AI 與生成式 AI 概念
★★★☆☆
L11402 鑑別式與生成式 AI 的整合應用
應用實例
在實務上常將鑑別式與生成式 AI 結合運用,以發揮兩者所長。例如,自駕車系統中運用鑑別式 AI 來偵測道路上的物體與做出判斷,同時利用生成式 AI 模擬各種道路場景以增強模型訓練資料;又如智慧語音助理結合語音辨識(鑑別式)與語音合成(生成式)技術,才能與使用者進行自然的語音互動。透過這類結合應用,可提升 AI 系統的效能並擴展其應用範疇。
L121 No code / Low code 概念
★★★★☆
L12101 No Code / Low Code 的基本概念
核心概念
「No Code」(無程式碼)與「Low Code」(低程式碼)是指幾乎不需撰寫程式碼就能開發應用的方式。這類工具平台提供圖形化介面和預先建構的模組,讓即使缺乏程式開發經驗的人也能透過拖拉元件、設定參數來建立應用程式或簡易的 AI 模型。
L121 No code / Low code 概念
★★★★☆
L12102 No Code / Low Code 的優勢與限制
優勢
採用 No Code/Low Code 平台的優勢在於大幅降低開發門檻、縮短開發時間,讓更多非技術背景的人員也能參與開發。
限制
限制則在於彈性較低(僅能使用平台提供的功能)、難以滿足高度客製化的需求,而且可能產生對特定平台的依賴。
L122 生成式 AI 應用領域與工具使用
★★★☆☆
L12201 生成式 AI 應用領域與常見工具
應用與工具
生成式 AI 可應用於多種領域,包括文本、圖像、聲音以及程式碼等,每個領域均有相應的工具支持:
- 文本生成:例如 OpenAI 的 GPT 模型(如 ChatGPT)和 Google 的 gemini 等對話式 AI。
- 圖像生成:例如 Midjourney、DALL-E 和 Stable Diffusion 等工具。
- 語音生成:例如語音克隆技術及文字轉語音(TTS)工具,如 ElevenLabs。
- 程式碼生成:例如 Github Copilot,常整合在 VS Code 等開發環境中,提供智慧程式碼自動完成功能。
L122 生成式 AI 應用領域與工具使用
★★★★☆
L12201 ChatGPT 技術架構
核心架構
ChatGPT 是 OpenAI 開發的對話式 AI 系統,其核心是一個基於大型語言模型 GPT(Generative Pre-trained Transformer, GPT)的模型。GPT 採用 Transformer 神經網路架構,Transformer 模型通常具有編碼器-解碼器(Encoder-Decoder)結構,但 GPT 僅使用其中的解碼器來進行自迴歸文本生成,並透過人類反饋強化學習(Reinforcement Learning from Human Feedback, RLHF)進行微調優化。經過海量語料的預訓練和人類回饋的對話調校,ChatGPT 能理解使用者的上下文並產生連貫且符合要求的回答。
L122 生成式 AI 應用領域與工具使用
★★★★★
L12202 提示工程 (Prompt Engineering)
核心概念
提示工程是指為生成式 AI 設計和優化輸入提示(Prompt)的技術,以有效引導模型產生符合期望的高品質回應。具體作法包括精確描述任務、提供範例或限制回答格式等,藉此控制模型輸出的風格和內容。例如,要求模型「以專家口吻解釋某概念」或提供回答步驟,都屬於提示工程的應用。透過良好的提示設計,可提升模型回應的相關性與正確性,降低產生不相關或不當內容的機會。
L122 生成式 AI 應用領域與工具使用
★★★★☆
L12202 檢索增強生成 (RAG)
核心概念
檢索增強生成(Retrieval-Augmented Generation, RAG)是一種結合資訊檢索與生成式 AI 的技術流程。在 RAG 中,模型在產生回答之前會先根據使用者的問題從外部知識庫或文件資料中檢索相關資訊,並將檢索到的內容作為輔助上下文提供給生成式模型。透過加入檢索階段,可提高生成結果的正確性和時效性,減少模型出現「幻覺」(hallucination,即捏造不實資訊)的情形。
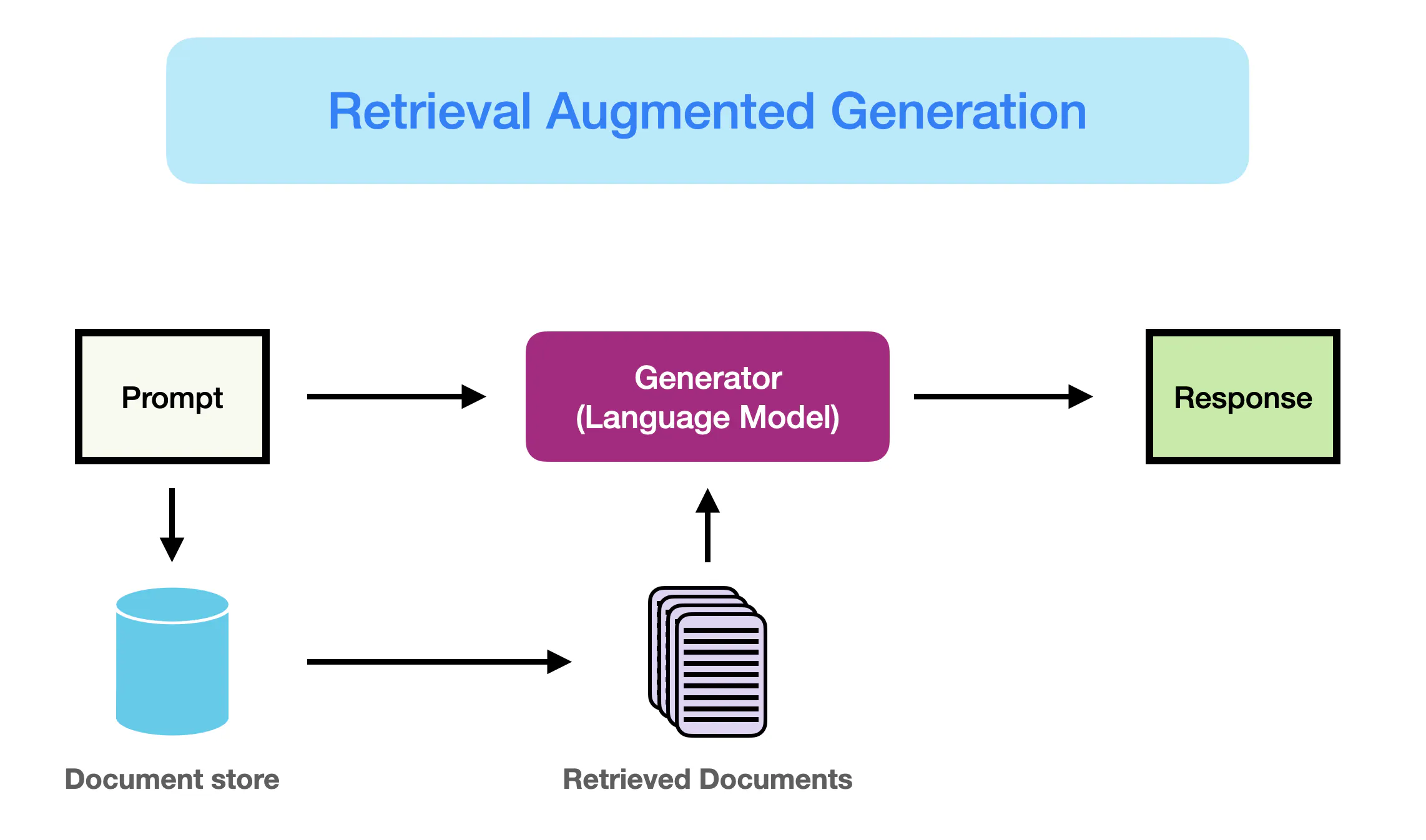
L123 生成式AI導入評估規劃
★★★★☆
L12301 生成式 AI 導入評估
評估要點
在導入生成式 AI 解決方案前,應先進行全面的可行性評估。需要確認所選技術或工具的效能能否滿足業務需求,並確保該解決方案適用於問題情境。此外,還要考量導入的成本效益,評估預期收益是否大於投入,包括人力、硬體和時間等成本,以判斷專案的商業價值。為提高評估嚴謹性,可參考相關單位發布的 AI 導入指引,確保各項考量周全。
L123 生成式AI導入評估規劃
★★★★☆
L12302 生成式 AI 導入規劃
規劃流程
規劃生成式 AI 導入時,需要有條理地安排各項工作。通常導入流程會依序包含:確認專案需求與目標、分配所需資源(人力、預算、技術等)、以及進行小規模的試點測試。透過這三個階段逐步驗證方案可行性並持續調整優化,確保 AI 專案能順利落地並達成預期目標。
L123 生成式AI導入評估規劃
★★★★★
L12303 生成式 AI 風險管理
風險面向
導入生成式 AI 時必須同步進行風險管理,以確保技術的安全可靠。首先要識別可能的倫理風險,例如模型產生偏見、有害內容或侵犯智慧財產權的情況;其次關注資料安全與隱私風險,確保訓練數據與生成結果符合法律規範,不洩露個人隱私;最後遵守相關法律法規的合規要求(例如版權、個資法等)。針對上述風險建立對應的防範措施與監控機制,才能落實負責任AI (Responsible AI)的應用。
沒有找到符合條件的重點。
↑