L11302 常見的機器學習模型
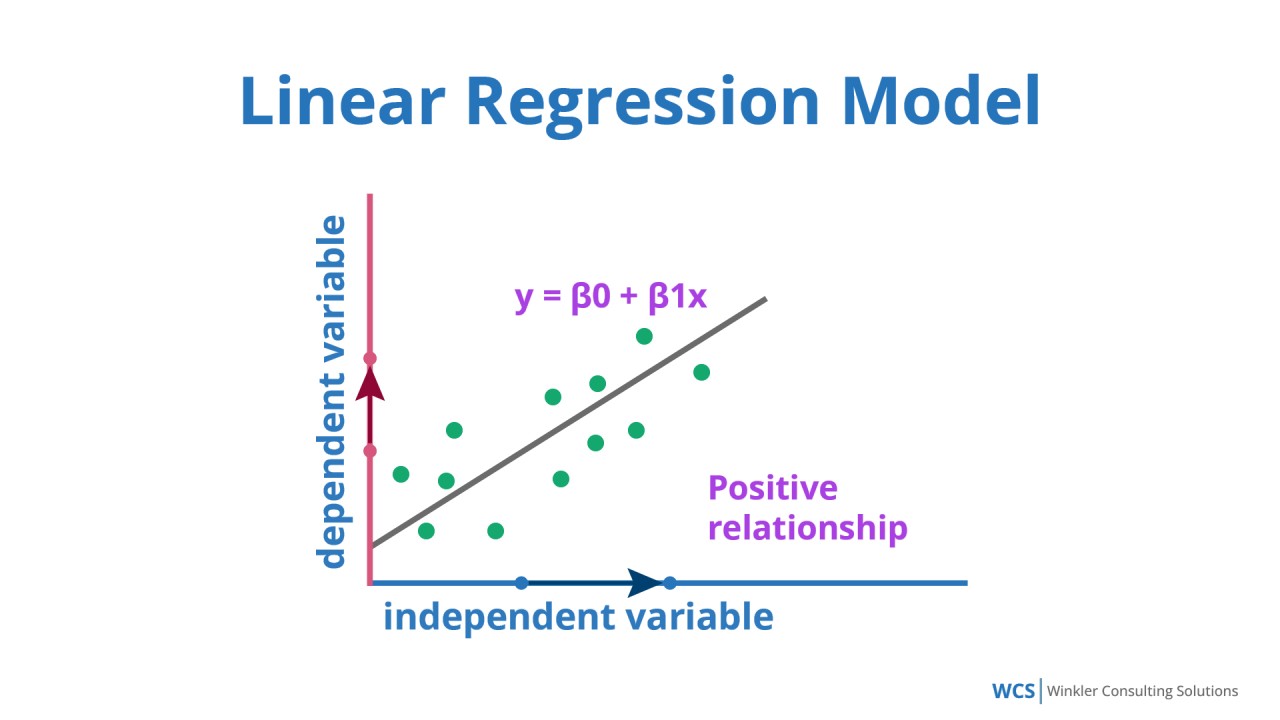
線性回歸(Linear Regression):
線性回歸是最基本的監督式學習算法,用於預測連續值,假設目標變量與特徵之間存在線性關係,通過最小化均方誤差來擬合最佳直線或超平面,廣泛應用於預測房價、銷售額等。
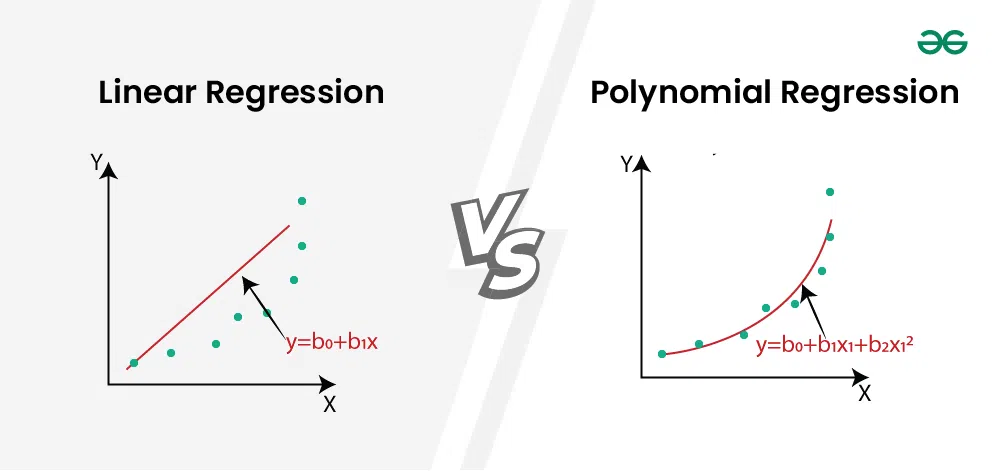
多項式回歸(Polynomial Regression):
多項式回歸是線性回歸的擴展,通過引入特徵的高次項(如x²、x³)來捕捉非線性關係,雖然模型形式更複雜,但本質上仍是線性模型,因為參數仍然是線性組合。
Lasso回歸(Lasso Regression):
Lasso回歸使用L1正則化(參數絕對值和),不僅可以減少過擬合,還能實現特徵選擇,因為它傾向於將不重要特徵的係數壓縮為零,產生稀疏解,適合高維資料。
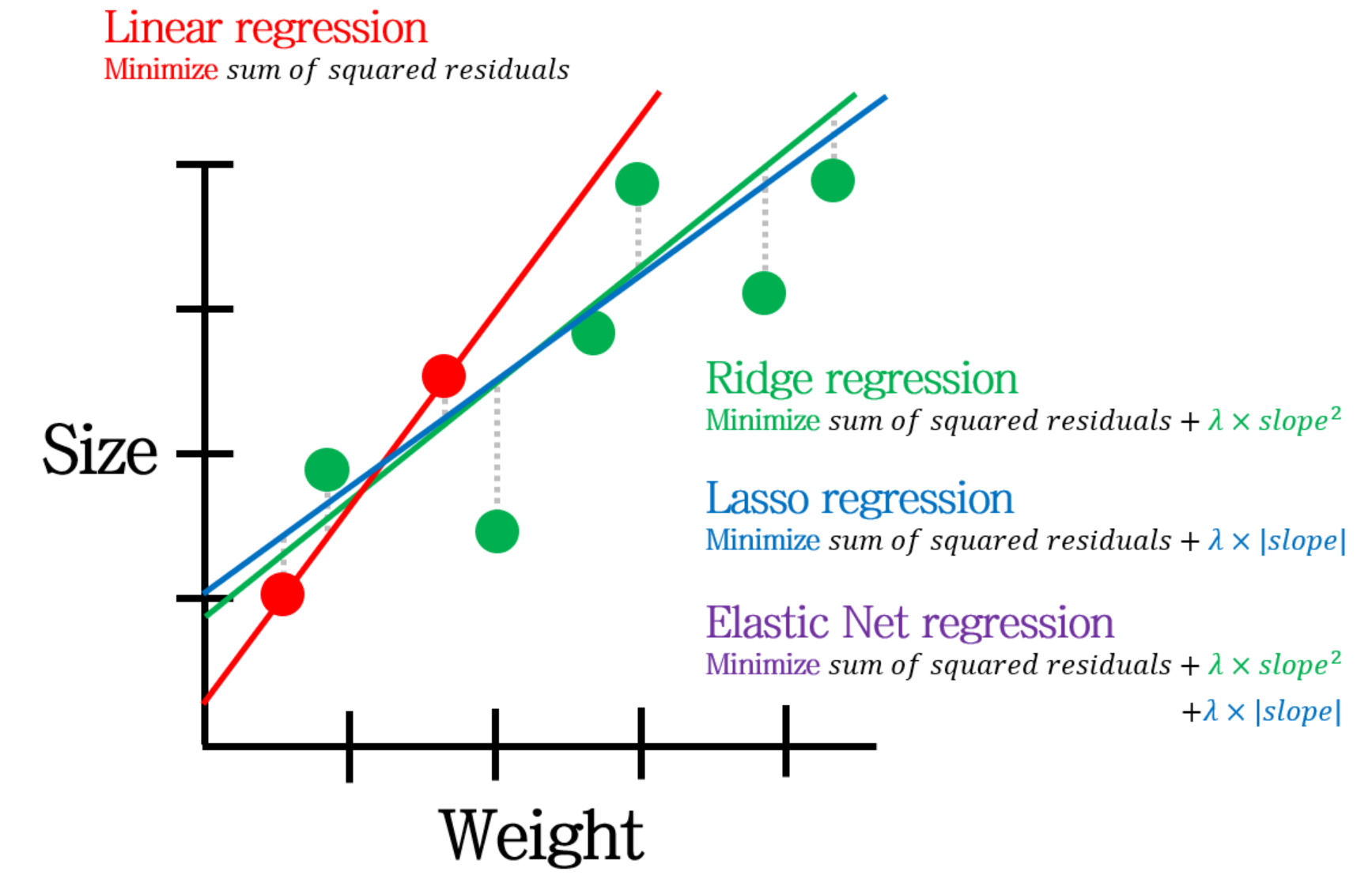
嶺回歸(Ridge Regression):
嶺回歸是線性回歸的正則化版本,通過添加L2正則化項(參數平方和)來減少過擬合,特別適用於特徵間存在多重共線性的情況,能夠產生更穩定的參數估計。
彈性網路(Elastic Net):
彈性網路結合了嶺回歸和Lasso回歸的優點,同時使用L1和L2正則化,既能處理多重共線性,又能實現特徵選擇,是一種更靈活的正則化回歸方法。
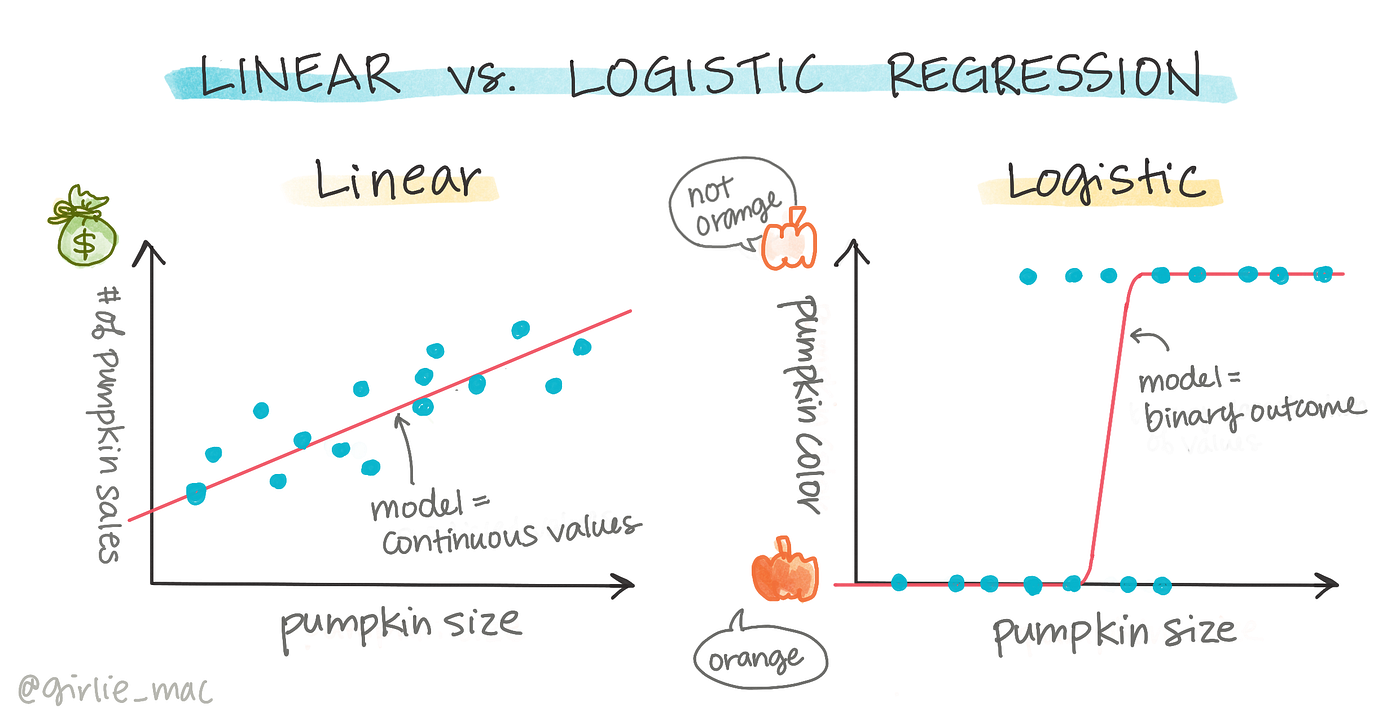
邏輯回歸(Logistic Regression):
邏輯回歸是一種用於二分類的監督式學習算法,使用邏輯函數(sigmoid函數)將線性模型的輸出轉換為0到1之間的概率,廣泛應用於醫療診斷、垃圾郵件檢測等領域。
多類別邏輯回歸:
多類別邏輯回歸擴展了二分類邏輯回歸,可以處理多類別分類問題,常用的實現方式有一對多(One-vs-Rest)和一對一(One-vs-One)策略,以及多項式邏輯回歸(softmax回歸)。
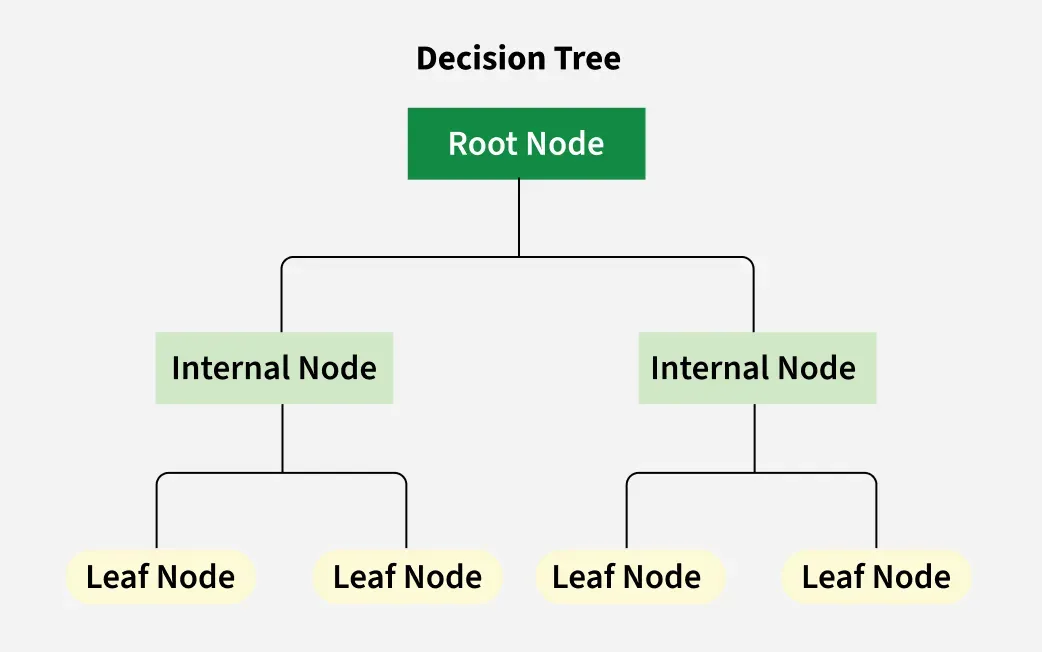
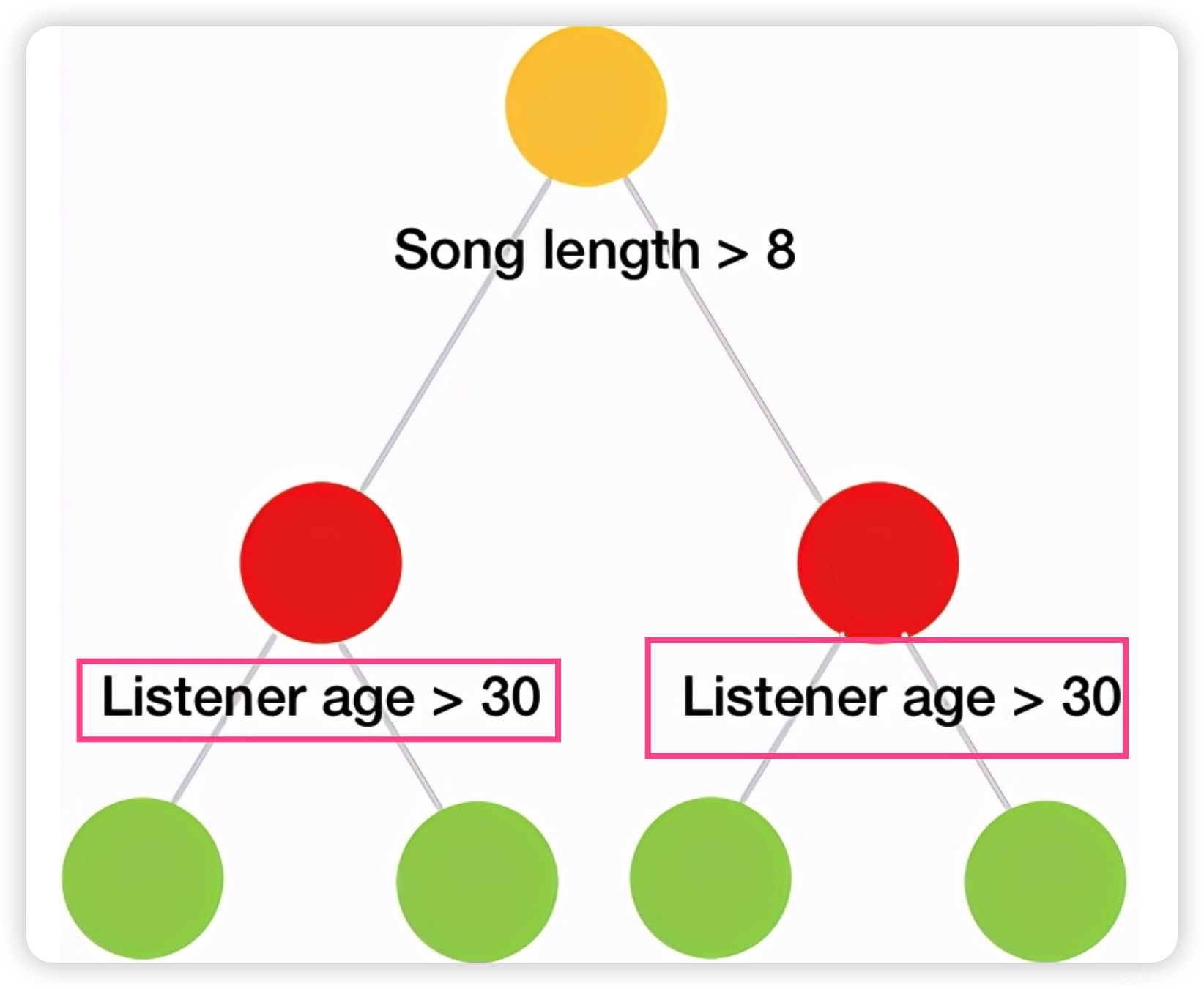
決策樹(Decision Tree):
決策樹是一種樹狀模型,通過一系列問題將資料分割成不同的子集,每個內部節點代表一個特徵測試,每個葉節點代表一個類別或值,具有高度可解釋性,但容易過擬合。
決策樹的分裂標準:
決策樹使用不同的標準來選擇最佳分裂特徵和閾值,常用的有信息增益(基於熵)、增益比、基尼不純度等,目標是使分裂後的子節點盡可能純淨。
決策樹的剪枝技術:
決策樹剪枝是防止過擬合的技術,包括預剪枝(在構建過程中提前停止)和後剪枝(先構建完整樹,再移除不重要的子樹),通過平衡模型複雜度和準確性來提高泛化能力。
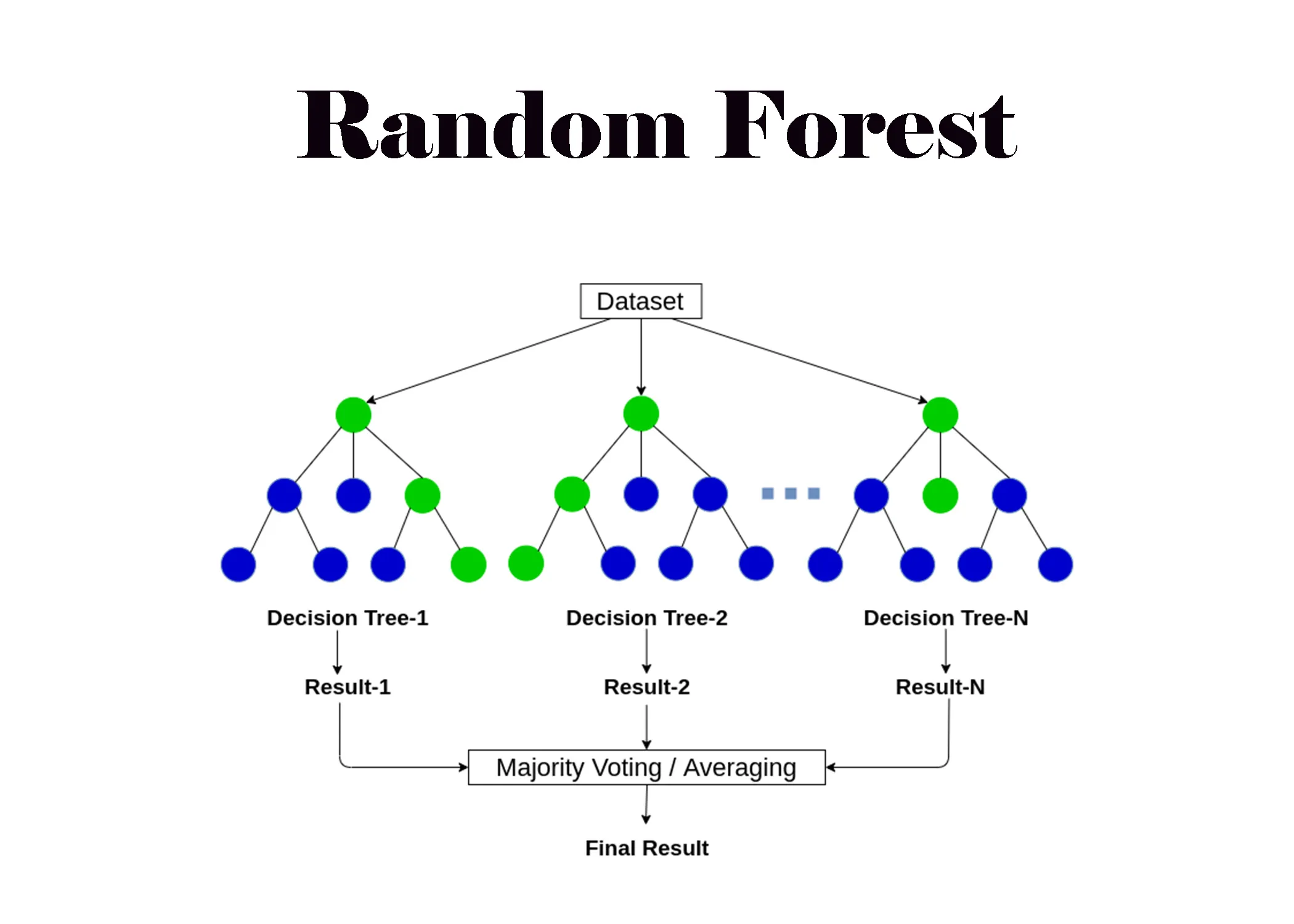
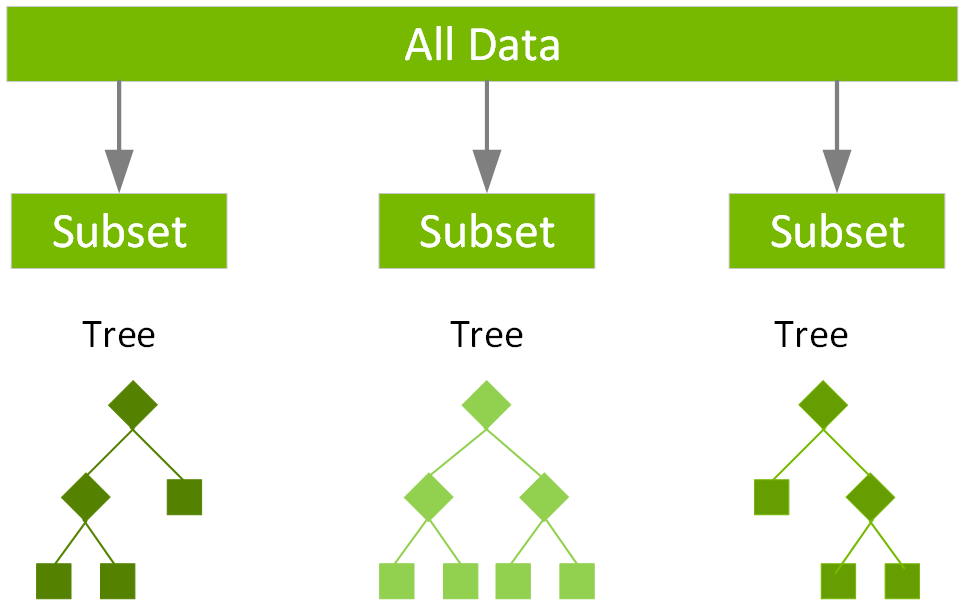
隨機森林(Random Forest):
隨機森林是一種集成學習方法,由多個決策樹組成,每棵樹使用隨機選擇的特徵和樣本(自助抽樣)訓練,最終結果由所有樹的預測結果投票或平均得出,具有較好的泛化能力和穩健性。
隨機森林的特徵重要性:
隨機森林可以評估特徵重要性,通常基於特徵對不純度的減少或對預測準確性的影響,這提供了模型的可解釋性,有助於理解哪些特徵對預測最為重要。
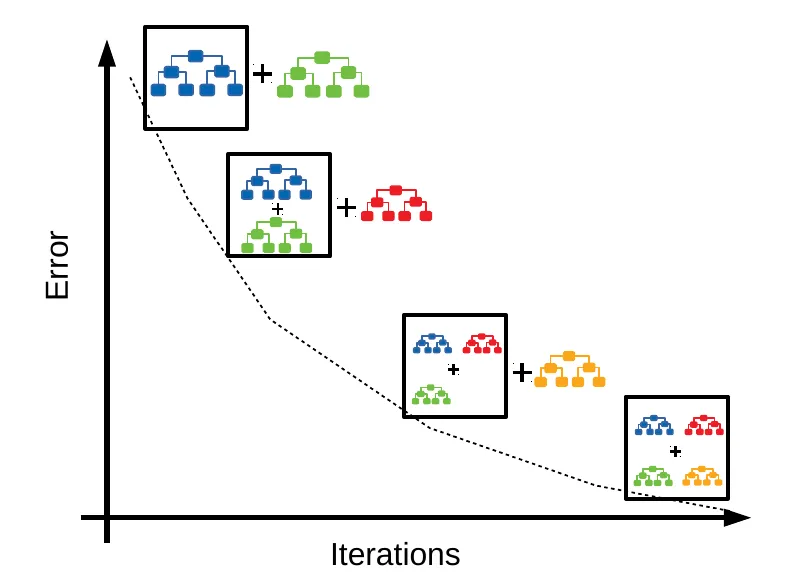
梯度提升樹(Gradient Boosting Trees):
梯度提升樹是一種序列化集成方法,通過迭代訓練新的樹來糾正前面樹的錯誤,每棵新樹擬合前面模型的殘差,最終模型是所有樹的加權和,具有很強的預測能力。
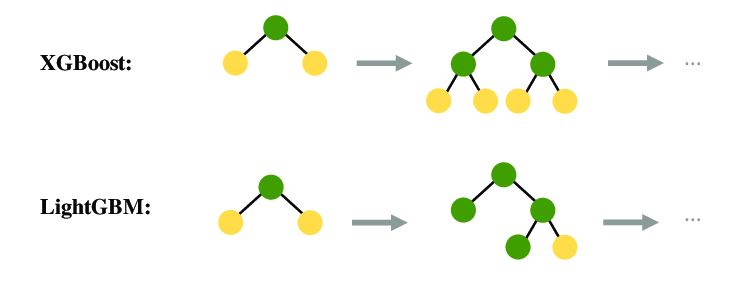
XGBoost:
XGBoost是梯度提升樹的高效實現,引入了正則化項控制模型複雜度,使用二階導數加速收斂,支持並行計算和樹剪枝,在各種機器學習競賽中表現優異,是最受歡迎的梯度提升實現之一。
LightGBM:
LightGBM是另一種高效的梯度提升實現,使用基於直方圖的算法和葉子優先生長策略,大幅減少內存使用和計算時間,特別適合大規模資料和高維特徵,同時保持高準確性。
CatBoost:
CatBoost是專為處理類別特徵設計的梯度提升實現,使用排序提升和創新的類別特徵編碼方法,減少過擬合,提高對類別特徵的處理能力,同時保持高效率和準確性。
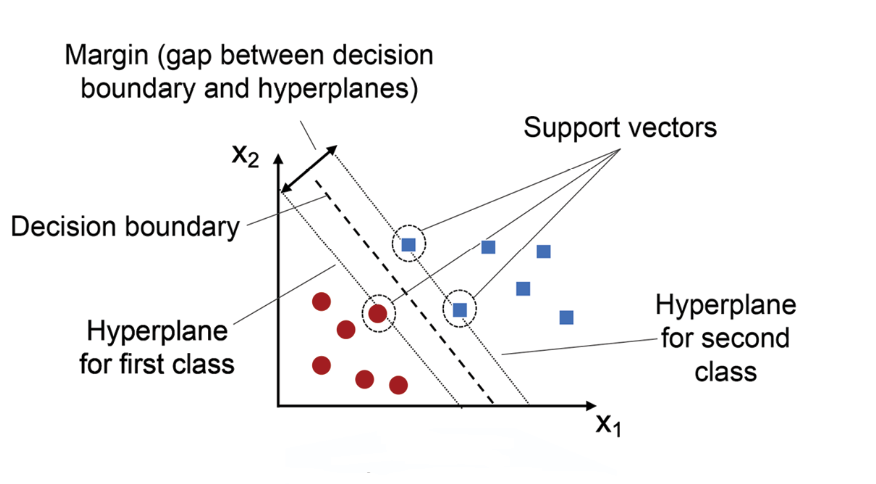
支持向量機(Support Vector Machine, SVM):
支持向量機是一種強大的監督式學習算法,通過尋找最大間隔超平面來分離不同類別的資料,只依賴少數支持向量,對噪聲和異常值較為穩健,使用核技巧可以處理非線性問題。
SVM的核函數:
SVM使用核函數將資料映射到高維空間,常用的核函數包括線性核、多項式核、徑向基函數(RBF)核和sigmoid核,不同核函數適用於不同類型的資料和問題。
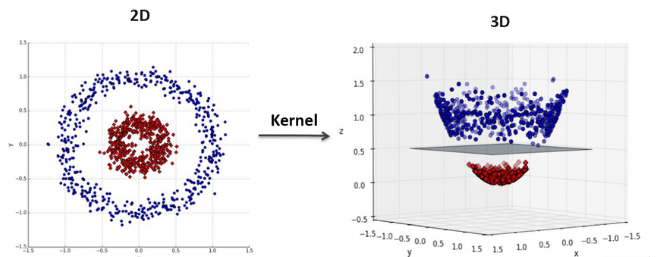
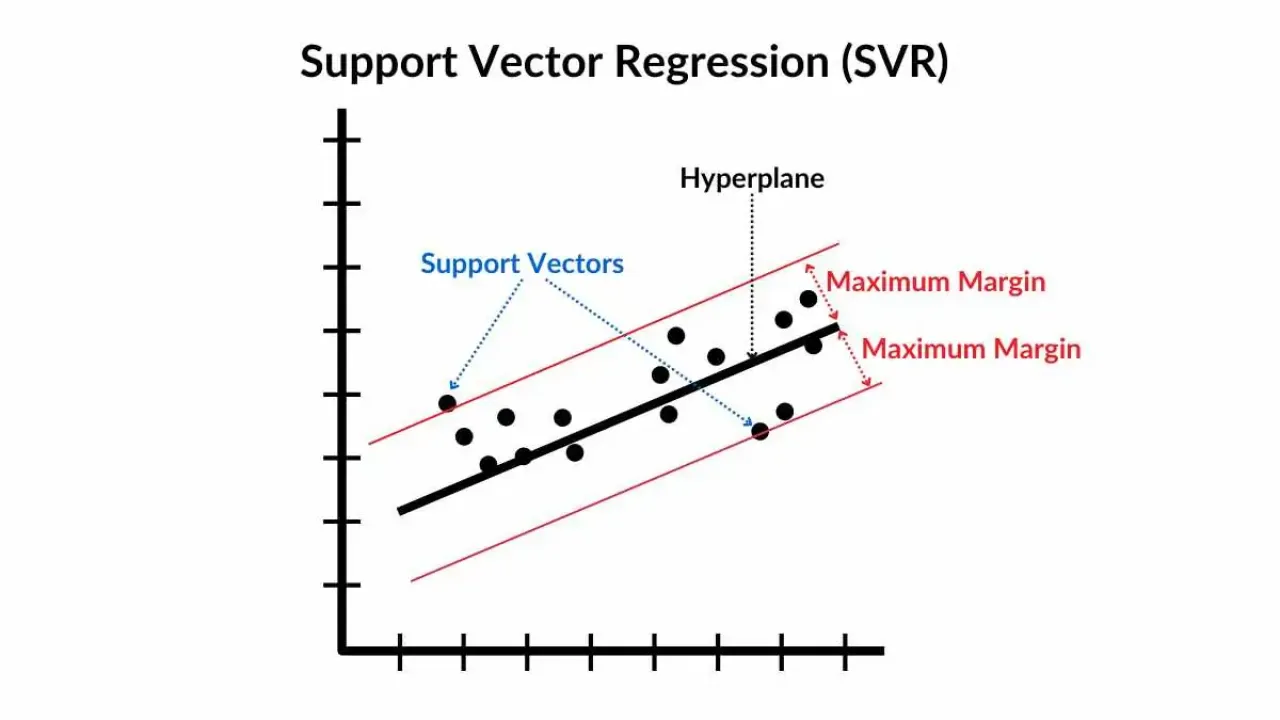
支持向量回歸(Support Vector Regression, SVR):
支持向量回歸是SVM的回歸版本,目標是找到一個函數,使得所有資料點與函數的偏差不超過ε,同時使函數盡可能平滑,適用於高維資料和非線性回歸問題。
K最近鄰(K-Nearest Neighbors, KNN):
K最近鄰是一種基於實例的學習方法,根據最接近的K個訓練樣本的類別或值來預測新樣本,不需要顯式訓練過程,但預測時計算成本高,對特徵縮放敏感。
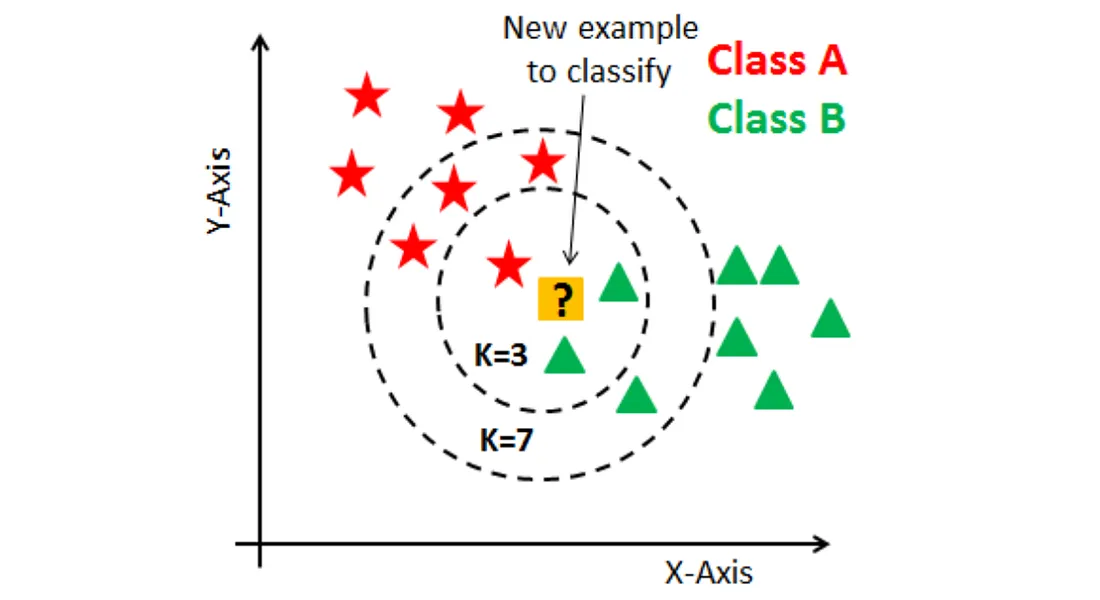
KNN的距離度量:
KNN算法中的「接近」由距離度量定義,常用的有歐氏距離、曼哈頓距離、閔可夫斯基距離和餘弦相似度等,不同的距離度量適用於不同類型的資料和問題。
朴素貝葉斯(Naive Bayes):
朴素貝葉斯是基於貝葉斯定理的監督式學習算法,假設特徵之間相互獨立(「朴素」假設),雖然這個假設在實際中很少成立,但算法在文本分類等高維問題中表現良好,計算效率高。
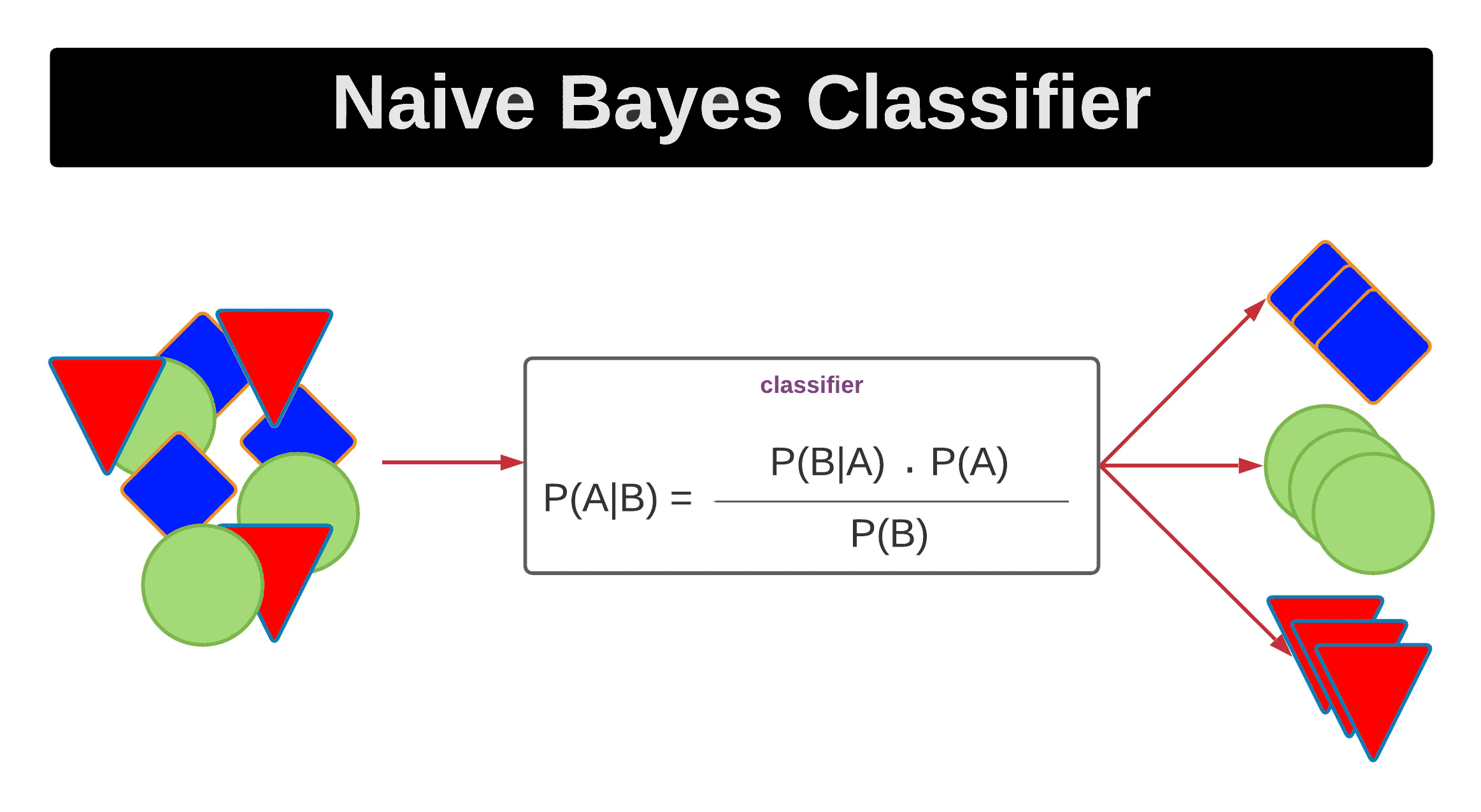
朴素貝葉斯的變體:
朴素貝葉斯有多種變體,包括高斯朴素貝葉斯(假設特徵服從高斯分佈,適用於連續特徵)、多項式朴素貝葉斯(適用於文本分類)和伯努利朴素貝葉斯(適用於二元特徵)。
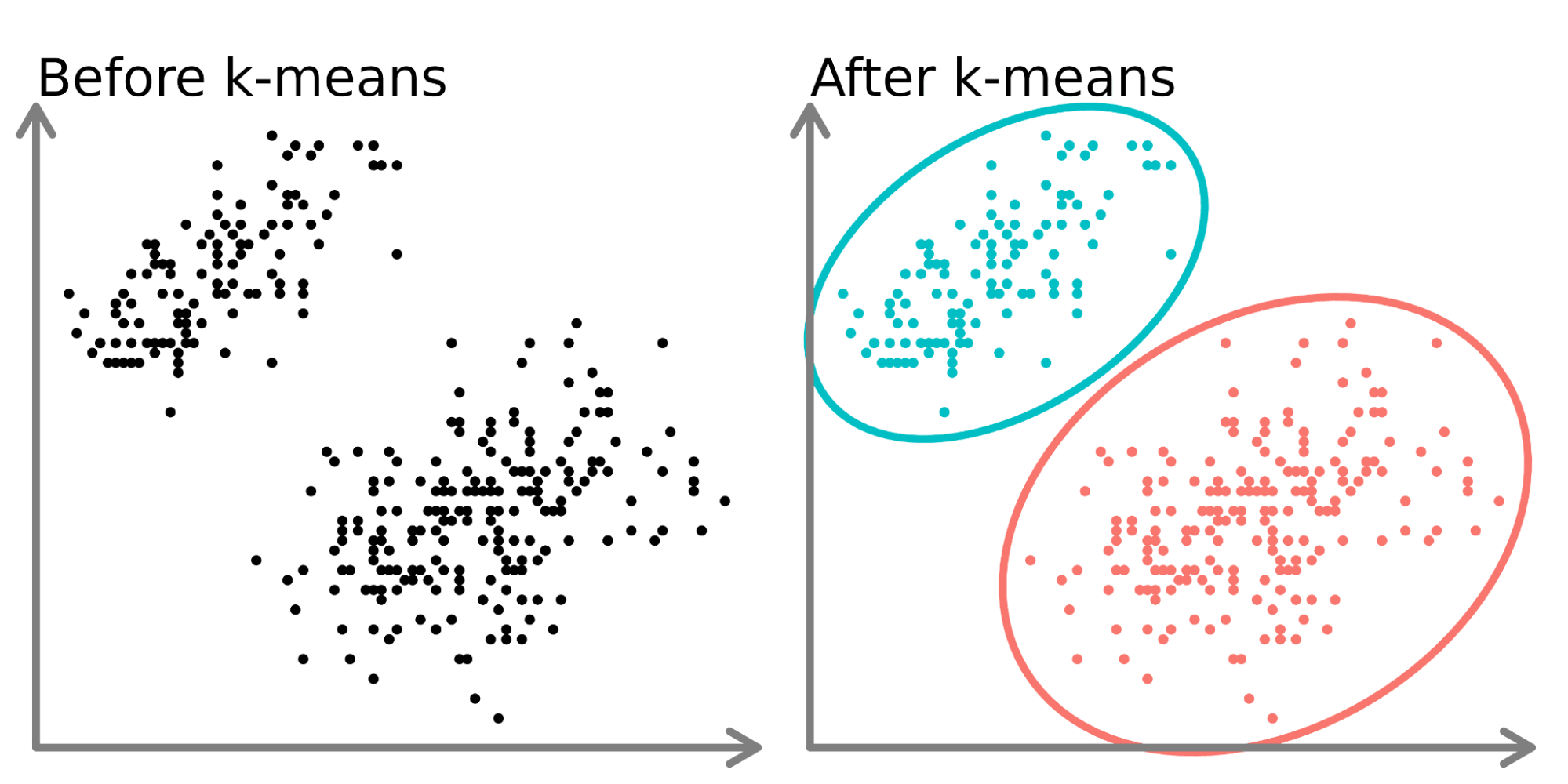
K均值聚類(K-means Clustering):
K均值聚類是一種基本的非監督式學習算法,將資料分為K個簇,每個資料點屬於與其最近的簇中心對應的簇,通過迭代優化簇中心位置,直到收斂,適用於發現資料中的自然分組。
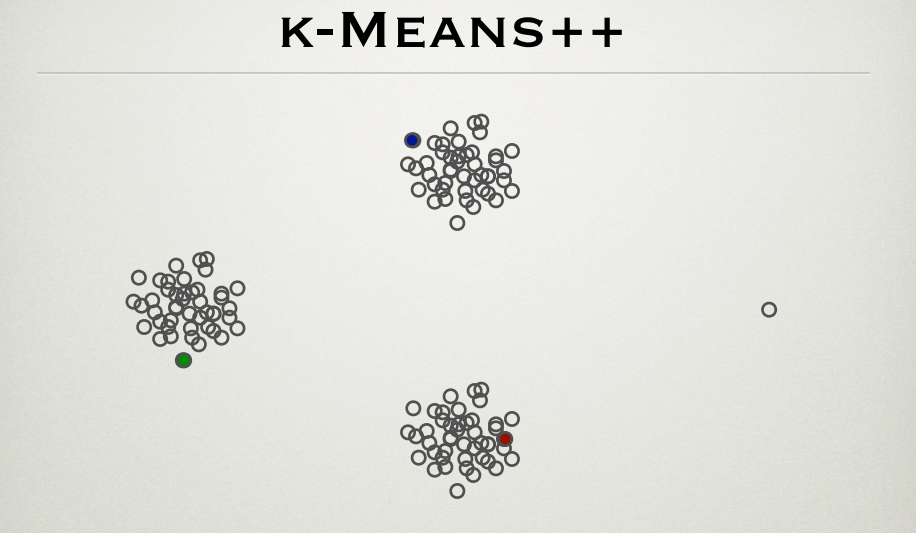
K均值++:
K均值++是K均值聚類的改進版,通過更智能的初始化簇中心(選擇相互距離較遠的點)來加速收斂並提高結果質量,減少了對初始簇中心選擇的敏感性。
層次聚類(Hierarchical Clustering):
層次聚類通過創建資料點的層次結構來進行聚類,分為自底向上(凝聚式)和自頂向下(分裂式)兩種方法,不需要預先指定簇的數量,結果可以用樹狀圖(dendrogram)可視化。

DBSCAN(Density-Based Spatial Clustering of Applications with Noise):
DBSCAN是一種基於密度的聚類算法,能夠發現任意形狀的簇,並識別噪聲點,不需要預先指定簇的數量,但需要設置密度參數,適用於發現非球形簇和處理噪聲資料。

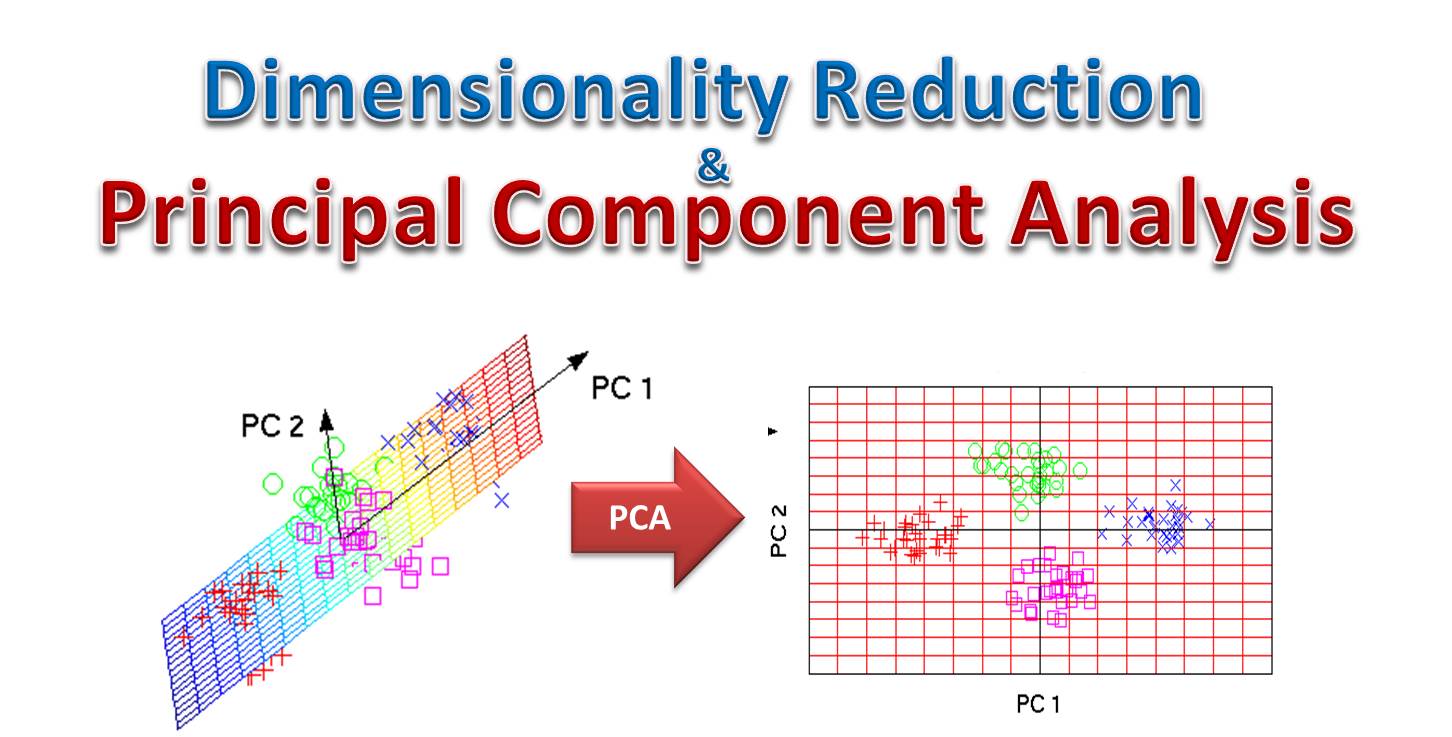
主成分分析(Principal Component Analysis, PCA):
主成分分析是一種降維技術,通過線性變換將高維資料投影到低維空間,保留最大方差的方向(主成分),用於資料壓縮、可視化和特徵提取,減少特徵間的相關性。
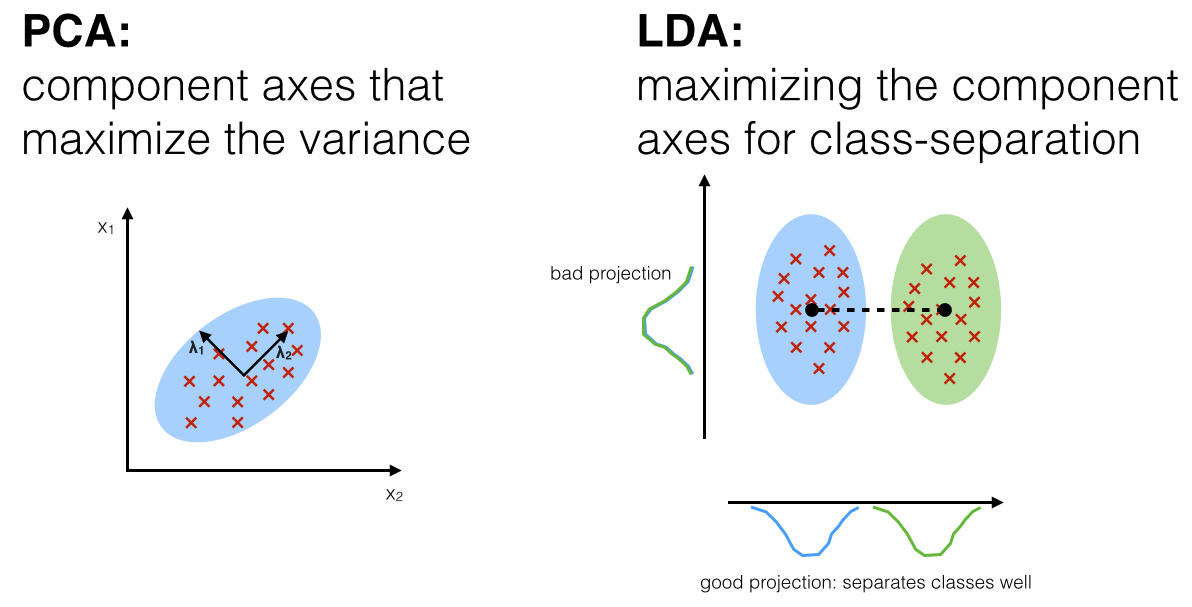
線性判別分析(Linear Discriminant Analysis, LDA):
線性判別分析是一種監督式降維技術,尋找能夠最大化類別間距離並最小化類別內距離的投影方向,既可用於降維,也可直接用於分類,特別適合多類別分類問題。
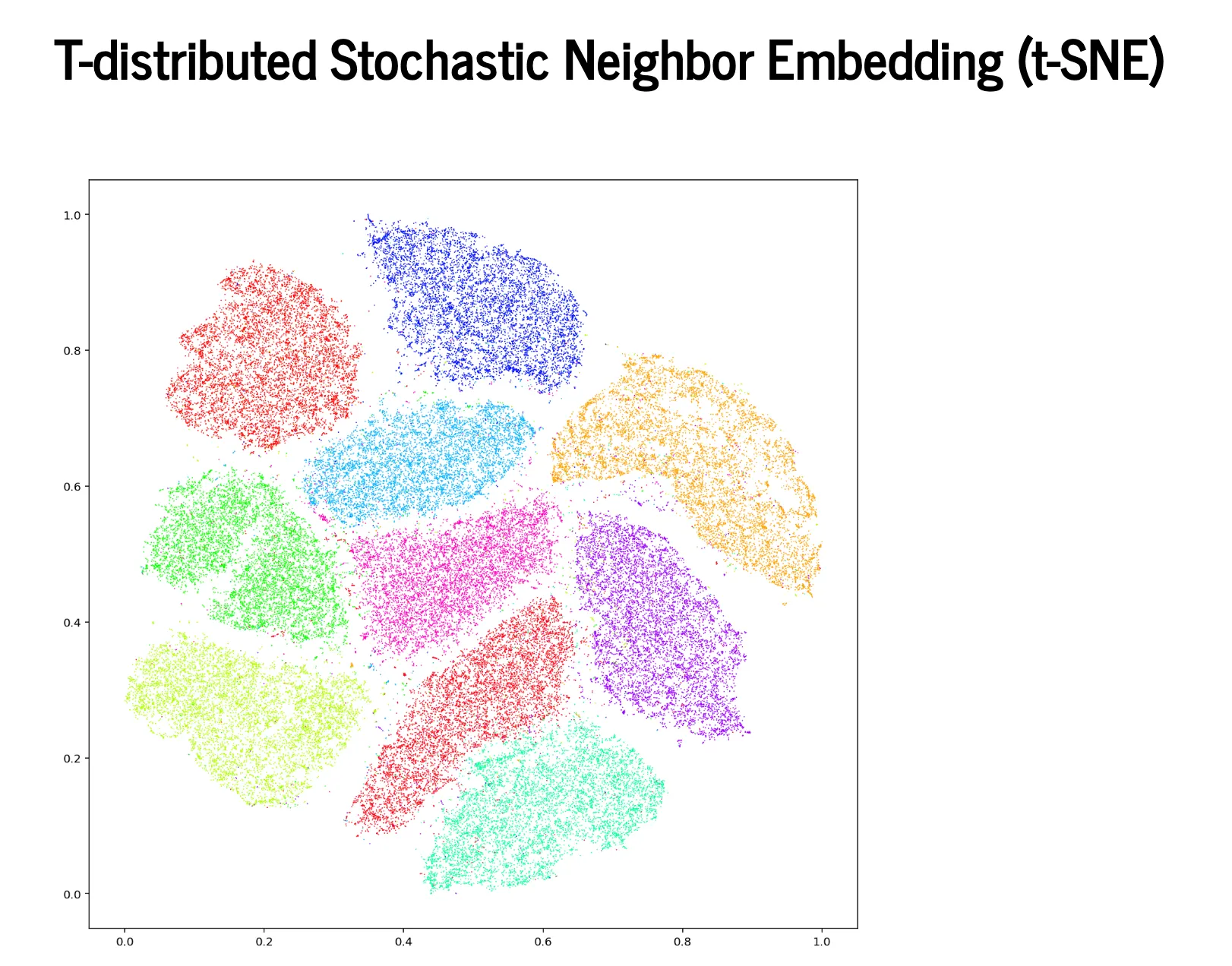
t-SNE(t-distributed Stochastic Neighbor Embedding):
t-SNE是一種非線性降維技術,特別適合高維資料的可視化,通過保持資料點之間的局部相似性,能夠揭示資料中的簇結構和模式,但計算成本高,不適合大規模資料。
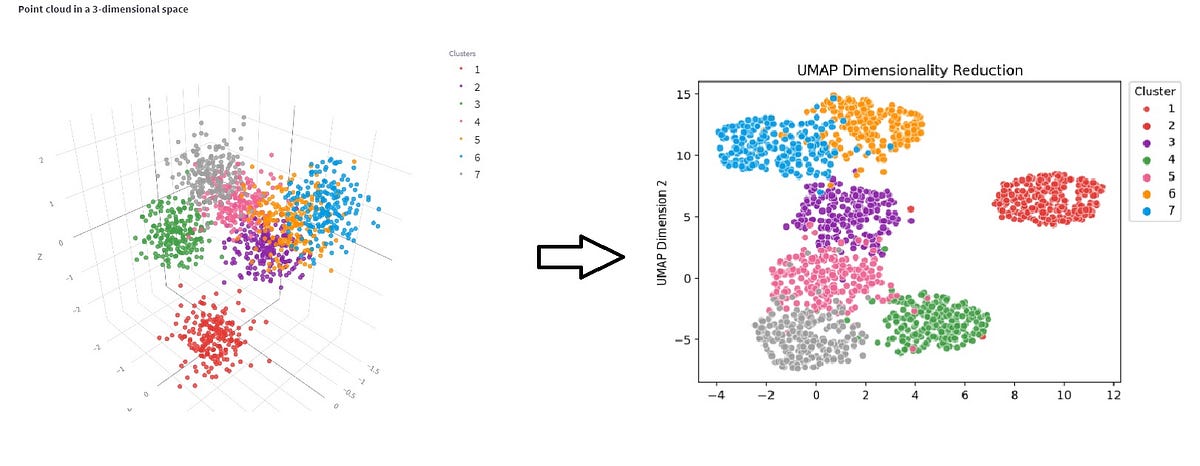
UMAP(Uniform Manifold Approximation and Projection):
UMAP是一種新型的降維技術,結合了數學理論和計算效率,能夠保持資料的全局結構和局部關係,比t-SNE更快,可擴展性更好,適用於大規模高維資料的可視化和降維。
關聯規則學習(Association Rule Learning):
關聯規則學習是發現資料中項目間關聯的方法,如「購買尿布的顧客也傾向於購買啤酒」,常用於市場籃分析,最著名的算法是Apriori和FP-Growth,用於發現頻繁項集和關聯規則。
異常檢測(Anomaly Detection):
異常檢測是識別資料中異常或罕見模式的技術,常用方法包括統計方法(如Z-score)、基於密度的方法(如LOF)、基於距離的方法(如孤立森林)和基於重建的方法(如自編碼器)。
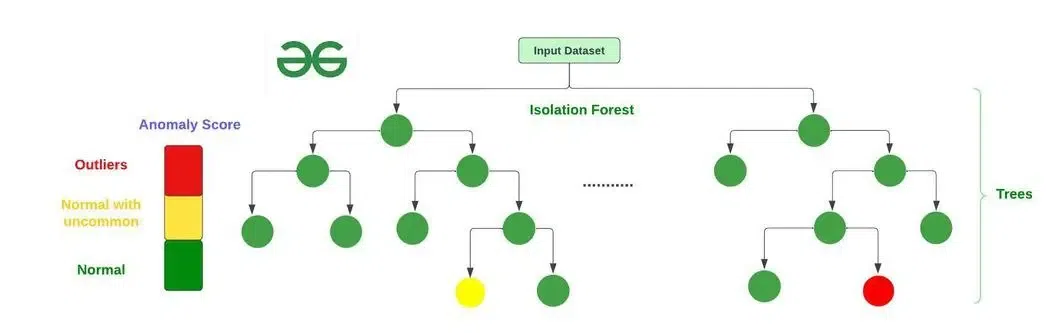
孤立森林(Isolation Forest):
孤立森林是一種高效的異常檢測算法,基於隨機森林的思想,通過隨機選擇特徵和分割點構建樹,異常點通常更容易被「孤立」,因此路徑長度較短,計算效率高,適用於高維資料。
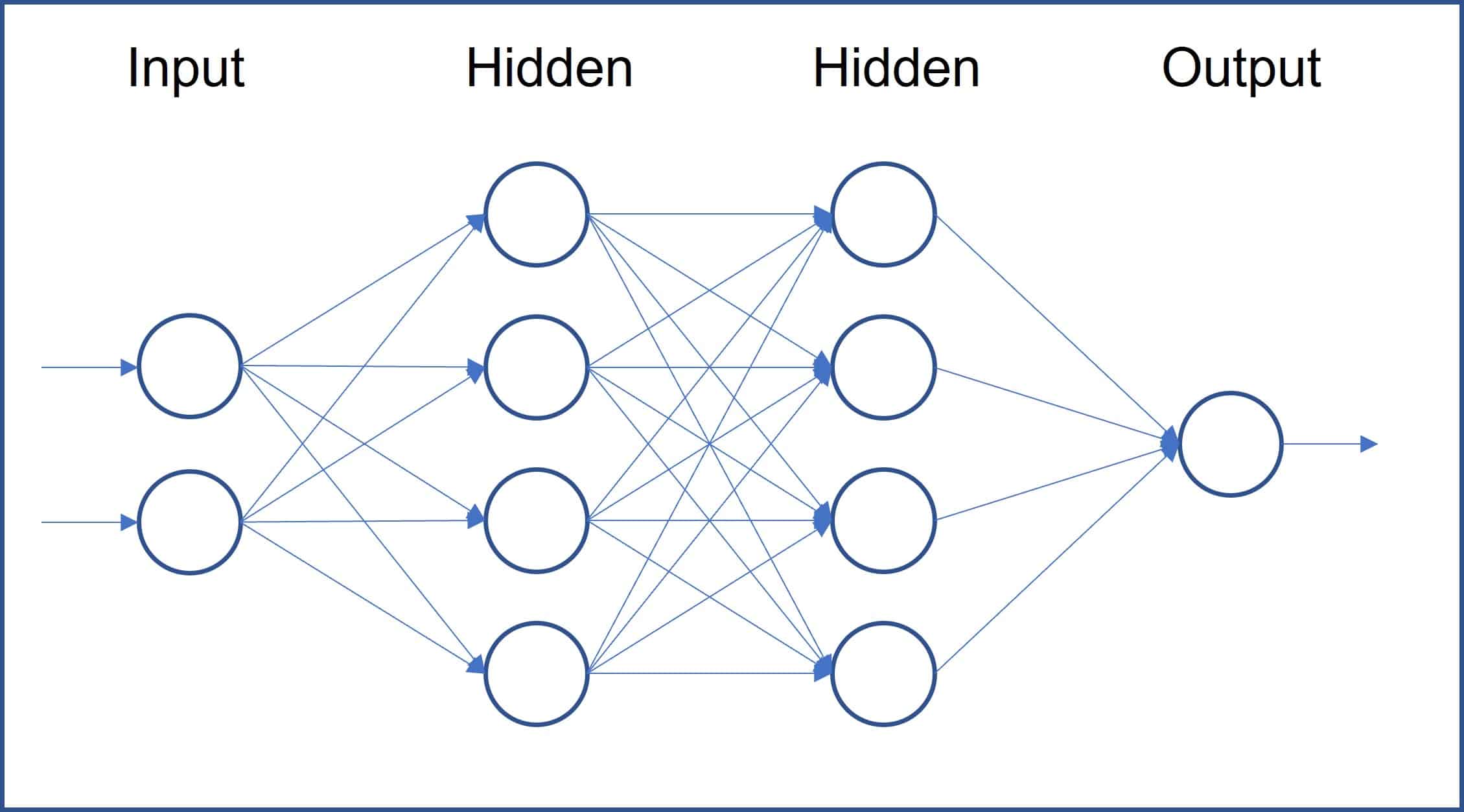
神經網路(Neural Network):
神經網路是由多層神經元組成的計算模型,通過反向傳播算法學習複雜的非線性關係,基本結構包括輸入層、隱藏層和輸出層,每個神經元通過激活函數處理輸入並產生輸出。
多層感知機(Multilayer Perceptron, MLP):
多層感知機是最基本的前饋神經網路,由多層全連接神經元組成,能夠學習複雜的非線性關係,適用於各種分類和回歸問題,是深度學習的基礎。
卷積神經網路(Convolutional Neural Network, CNN):
卷積神經網路是專門用於處理網格結構資料(如圖像)的神經網路,核心組件是卷積層、池化層和全連接層,通過局部連接和權重共享減少參數數量,在計算機視覺任務中表現優異。
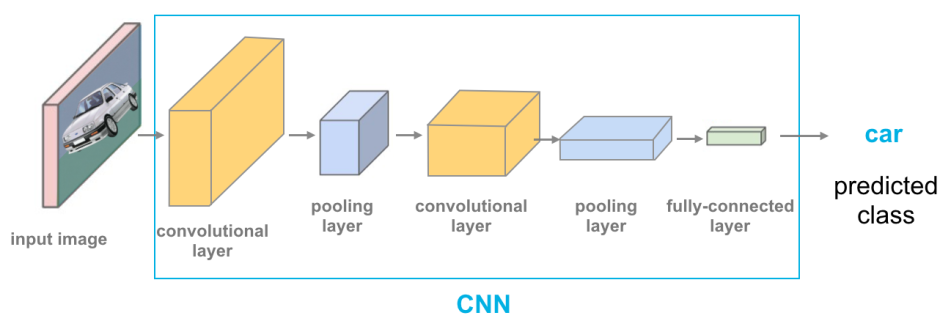
CNN的基本組件:
CNN的基本組件包括卷積層(提取局部特徵)、池化層(降低維度,提高穩健性)、激活函數(引入非線性)和全連接層(綜合特徵進行最終預測),這些組件共同構成了強大的視覺模式識別系統。
經典CNN架構:
經典的CNN架構包括LeNet(手寫數字識別)、AlexNet(首次在ImageNet上取得突破)、VGGNet(簡潔的架構設計)、GoogLeNet/Inception(引入Inception模塊)和ResNet(引入殘差連接,解決深層網路的梯度問題)。
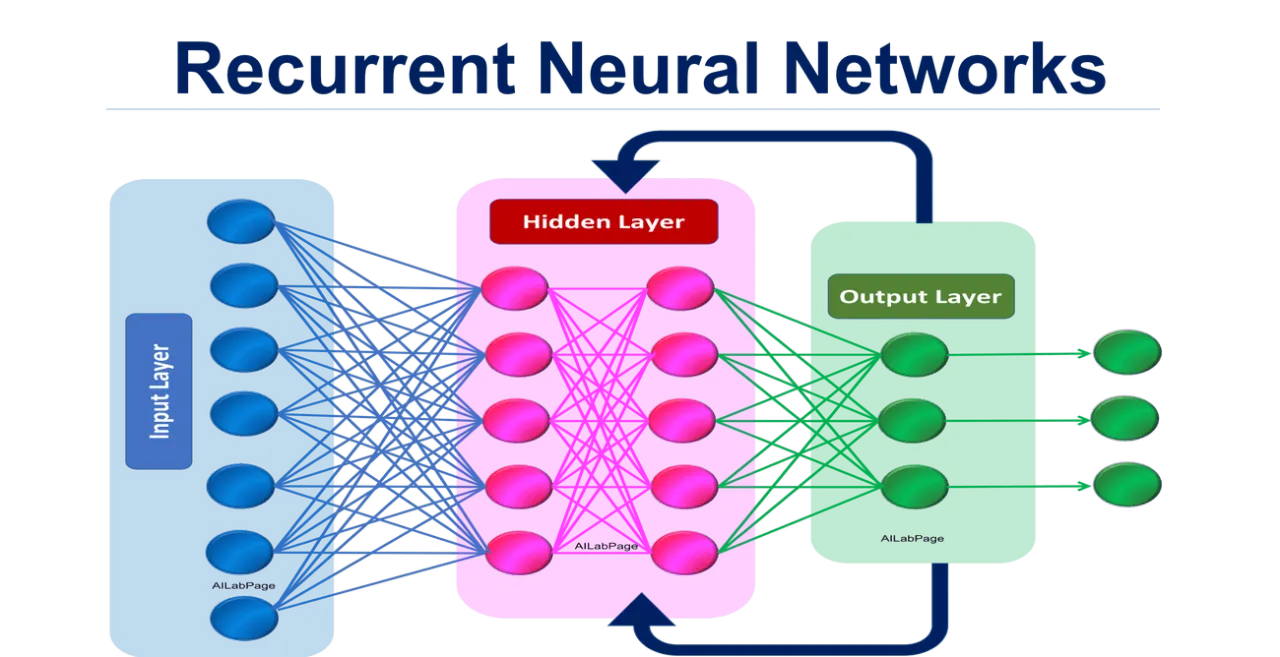
循環神經網路(Recurrent Neural Network, RNN):
循環神經網路是專門處理序列資料的神經網路,通過引入循環連接,使網路具有「記憶」能力,能夠捕捉序列中的時間依賴關係,適用於自然語言處理、時間序列分析等任務。
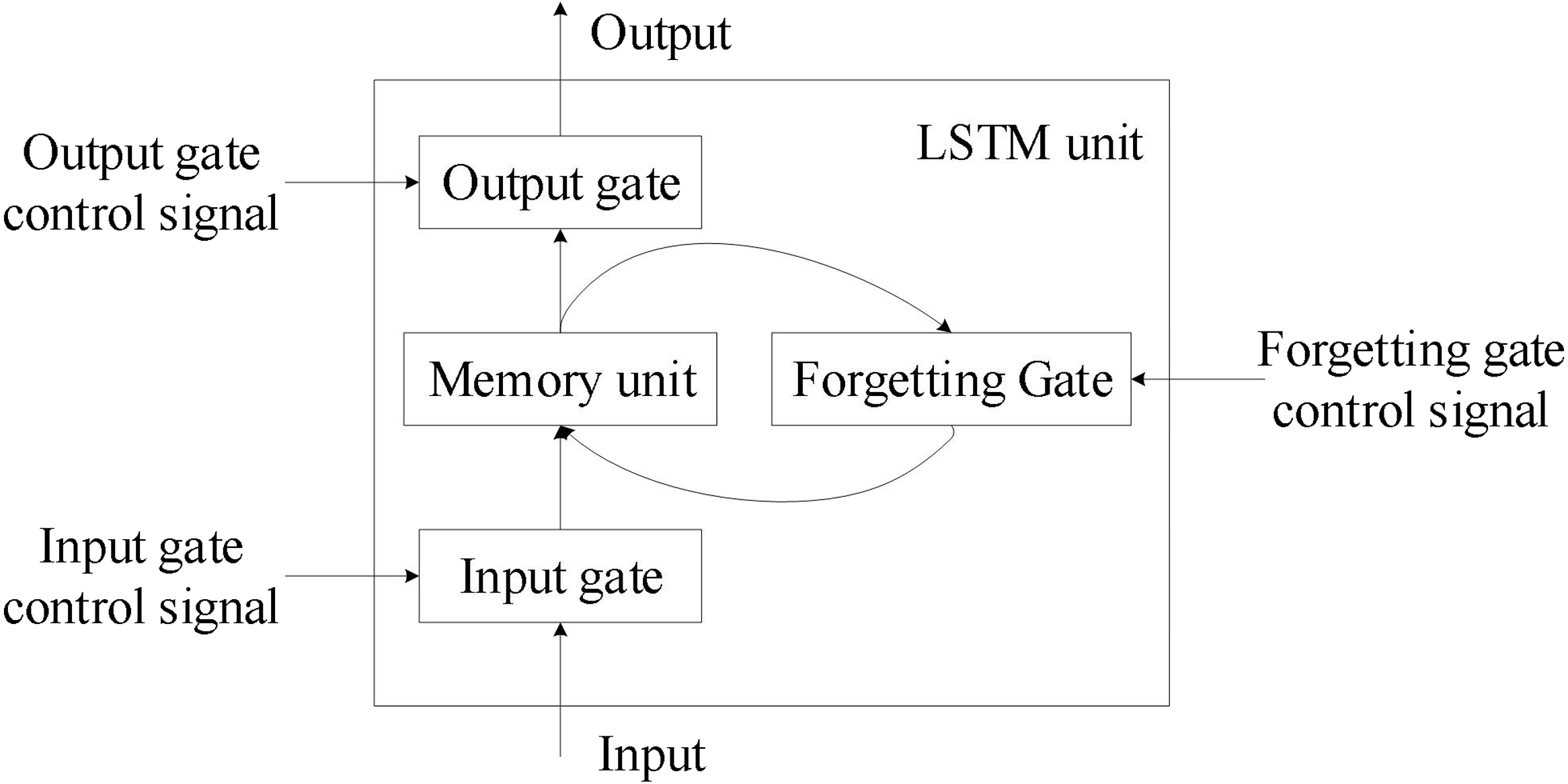
長短期記憶網路(Long Short-Term Memory, LSTM):
長短期記憶網路是一種特殊的RNN,設計用來解決傳統RNN的梯度消失問題,通過引入門控機制(輸入門、遺忘門和輸出門)控制信息流,能夠學習長期依賴關係,在序列建模任務中表現優異。
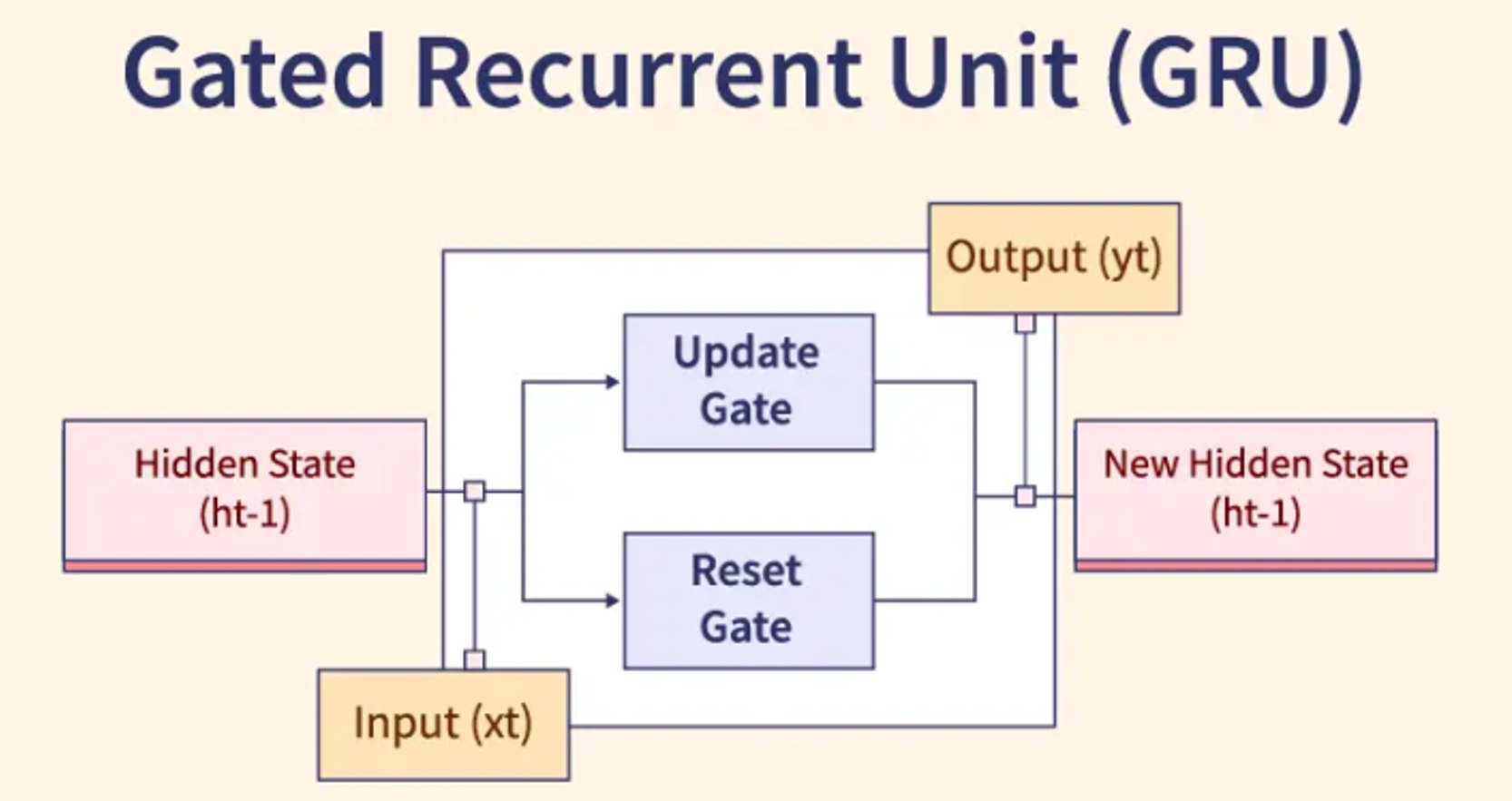
閘門循環單元(Gated Recurrent Unit, GRU):
閘門循環單元是LSTM的簡化版本,只有更新門和重置門,參數更少,訓練更快,在許多任務上性能與LSTM相當,是序列建模的另一個流行選擇。
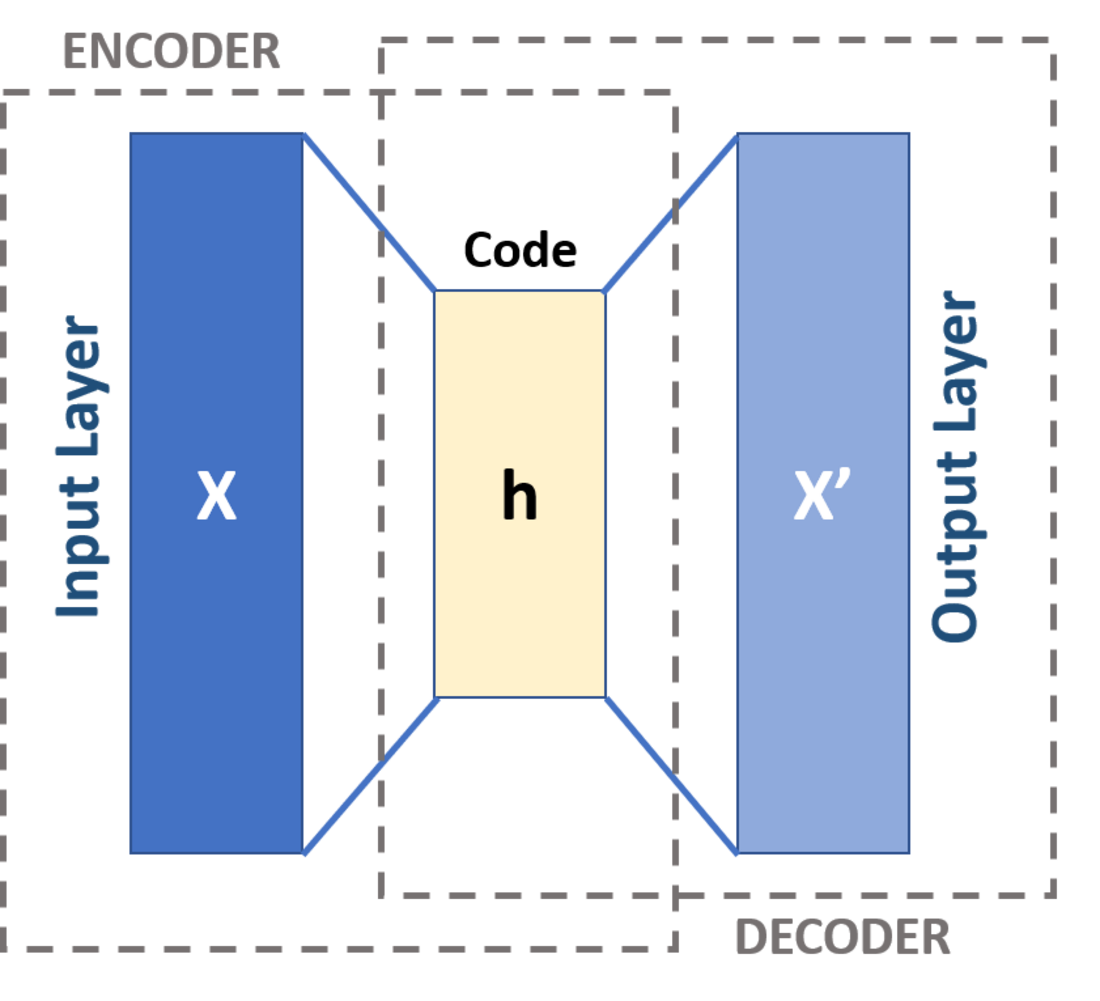
自編碼器(Autoencoder):
自編碼器是一種無監督學習神經網路,通過學習將輸入編碼為低維表示,然後重建原始輸入,用於降維、特徵學習、去噪和異常檢測,核心組件是編碼器和解碼器。
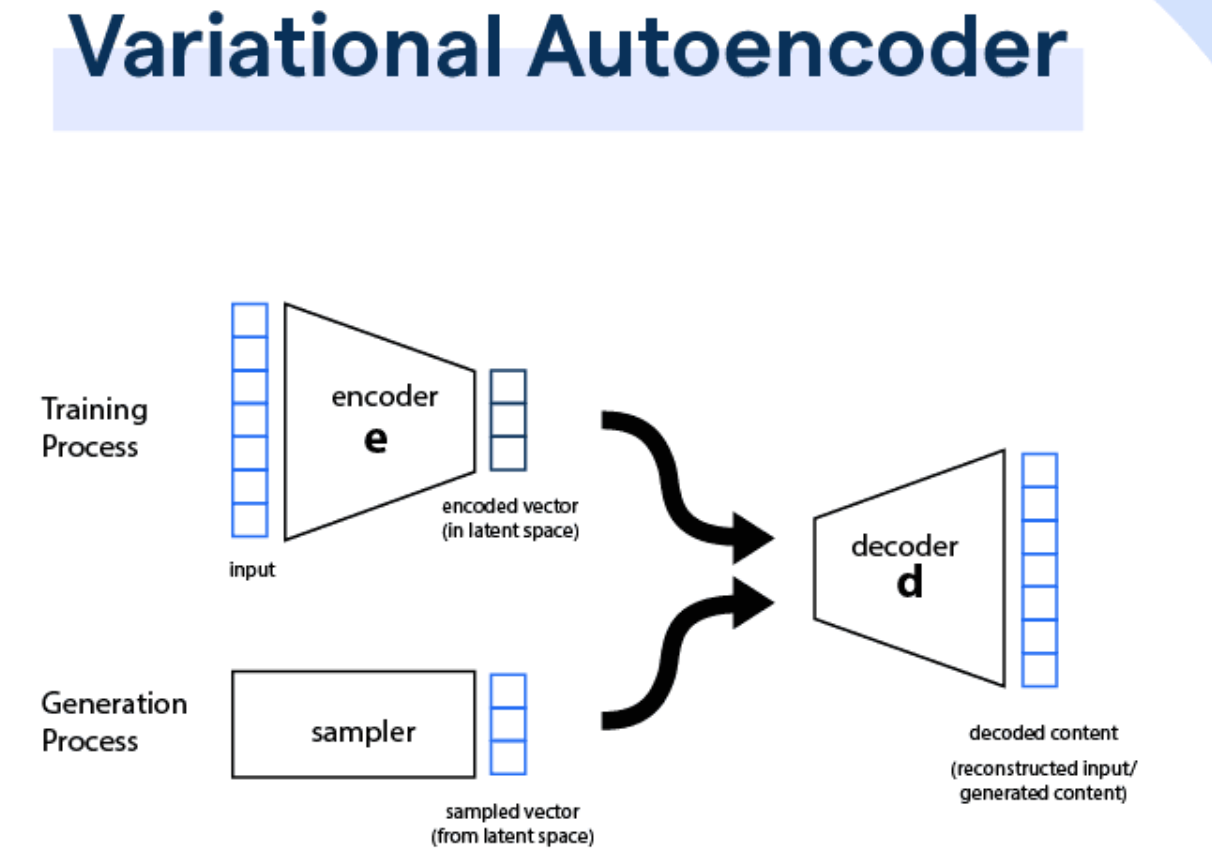
變分自編碼器(Variational Autoencoder, VAE):
變分自編碼器是自編碼器的概率版本,通過引入變分推斷,學習資料的潛在概率分佈,不僅可以重建輸入,還可以生成新的樣本,是一種強大的生成模型。
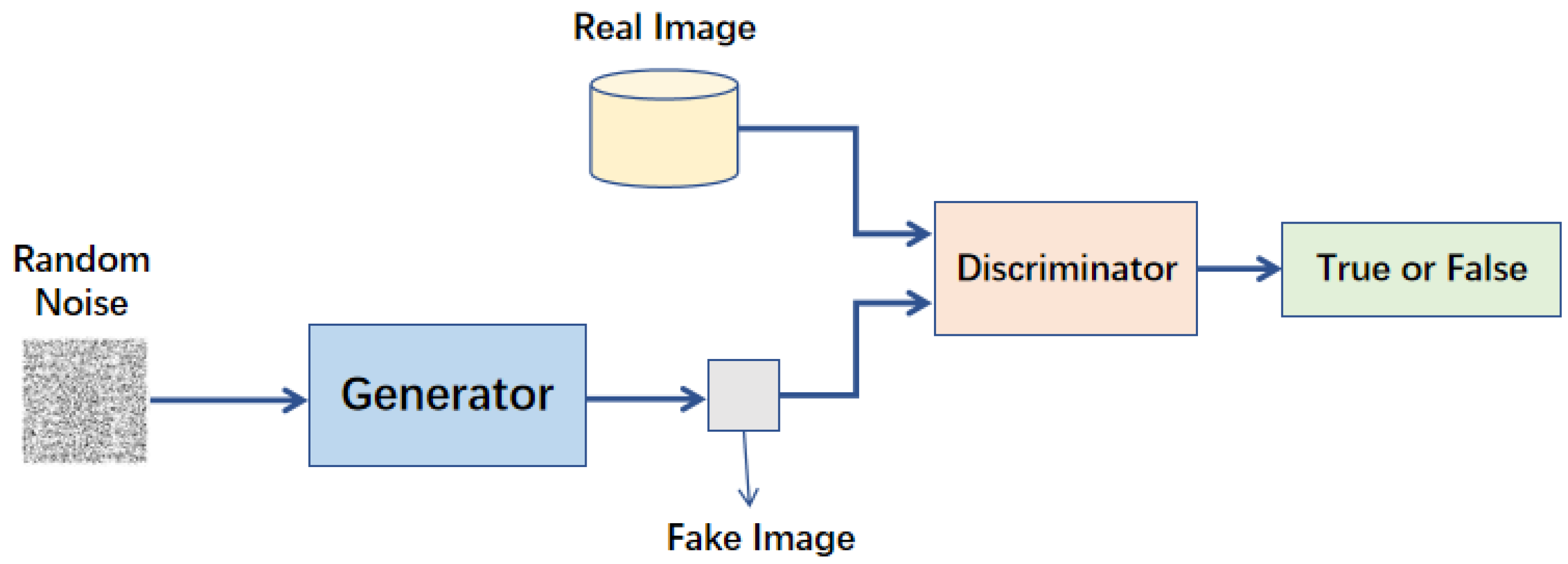
生成對抗網路(Generative Adversarial Network, GAN):
生成對抗網路是一種生成模型,由生成器和判別器兩個網路組成,通過對抗訓練學習生成逼真的資料,生成器試圖生成真實樣本,判別器試圖區分真實和生成的樣本,在圖像生成、風格轉換等領域有廣泛應用。
GAN的變體:
GAN有多種變體,包括DCGAN(深度卷積GAN)、CGAN(條件GAN)、CycleGAN(循環一致性GAN)、StyleGAN(風格GAN)和WGAN(Wasserstein GAN),每種變體都針對特定問題或改進特定方面。
Transformer:
Transformer是一種基於自注意力機制的神經網路架構,不使用循環或卷積,通過並行處理序列中的所有位置,捕捉長距離依賴關係,在自然語言處理任務中取得了突破性進展,是BERT、GPT等模型的基礎。
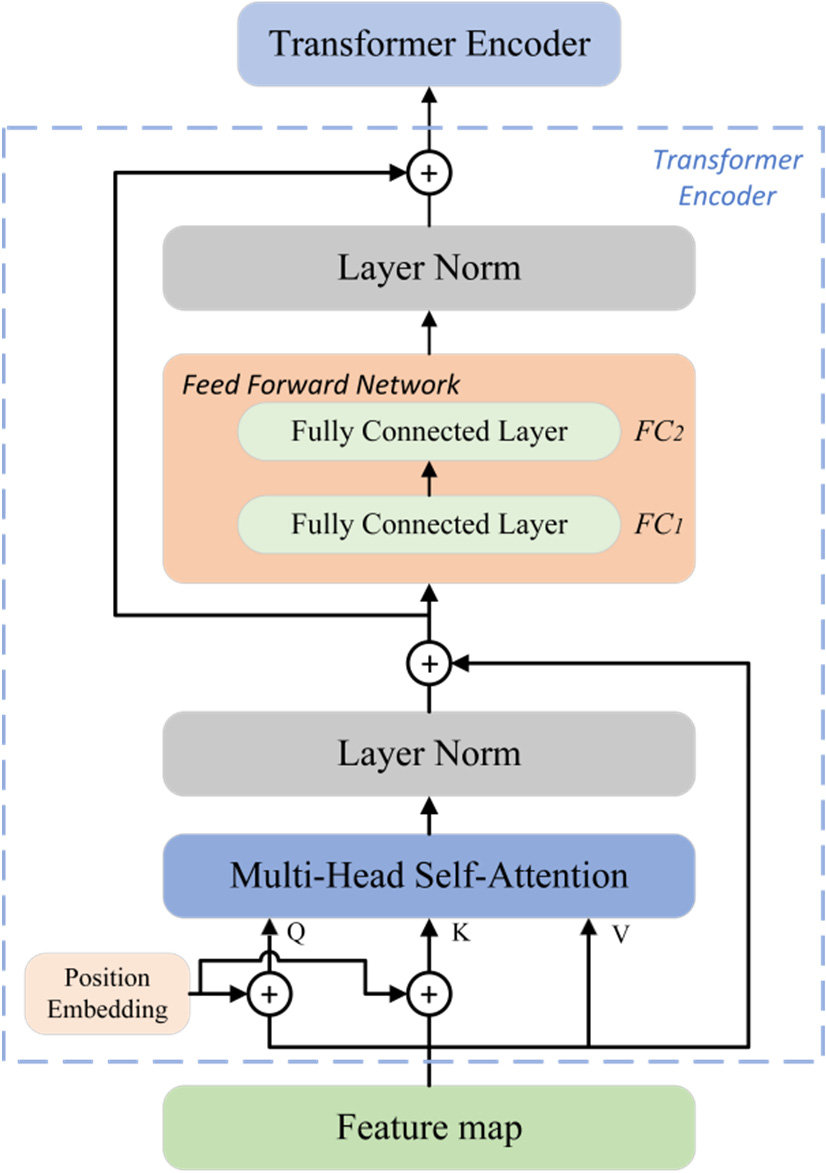
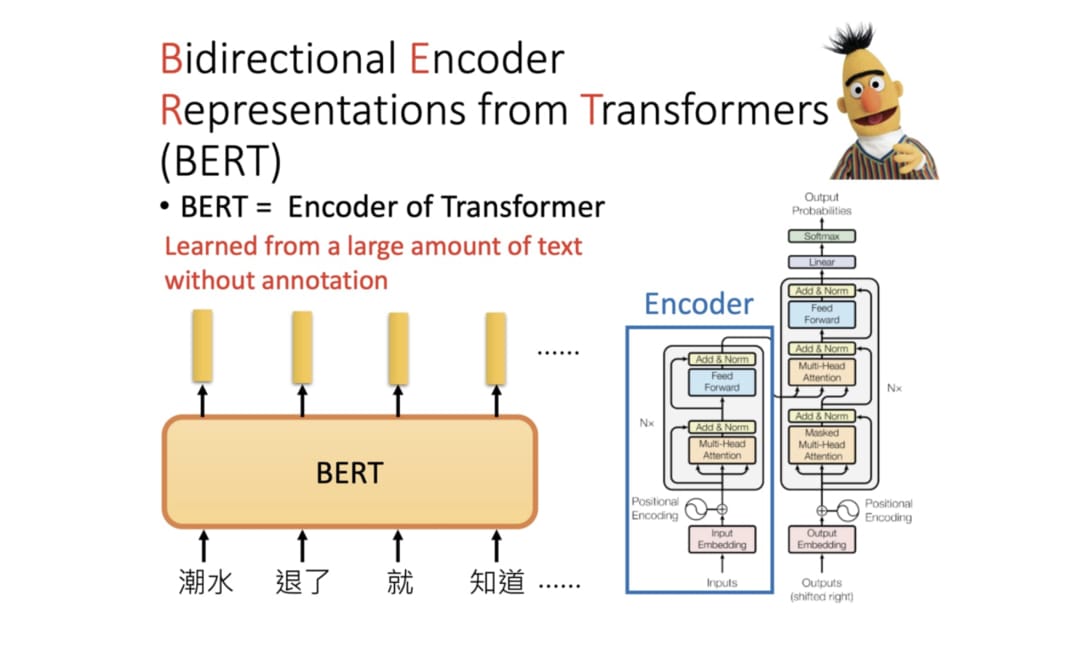
BERT(Bidirectional Encoder Representations from Transformers):
BERT是一種預訓練語言模型,基於Transformer編碼器,通過雙向上下文學習單詞表示,在多種自然語言處理任務上取得了最先進的結果,可以通過微調適應特定任務。
GPT(Generative Pre-trained Transformer):
GPT是一種預訓練語言模型,基於Transformer解碼器,通過自迴歸方式學習單詞序列,能夠生成連貫的文本,GPT-3和GPT-4等大型模型展示了強大的文本生成和理解能力。
集成學習(Ensemble Learning):
集成學習是結合多個基本模型以提高整體性能的方法,主要技術包括Bagging(如隨機森林)、Boosting(如AdaBoost、梯度提升)和Stacking(多層模型堆疊),通過減少方差或偏差來提高泛化能力。
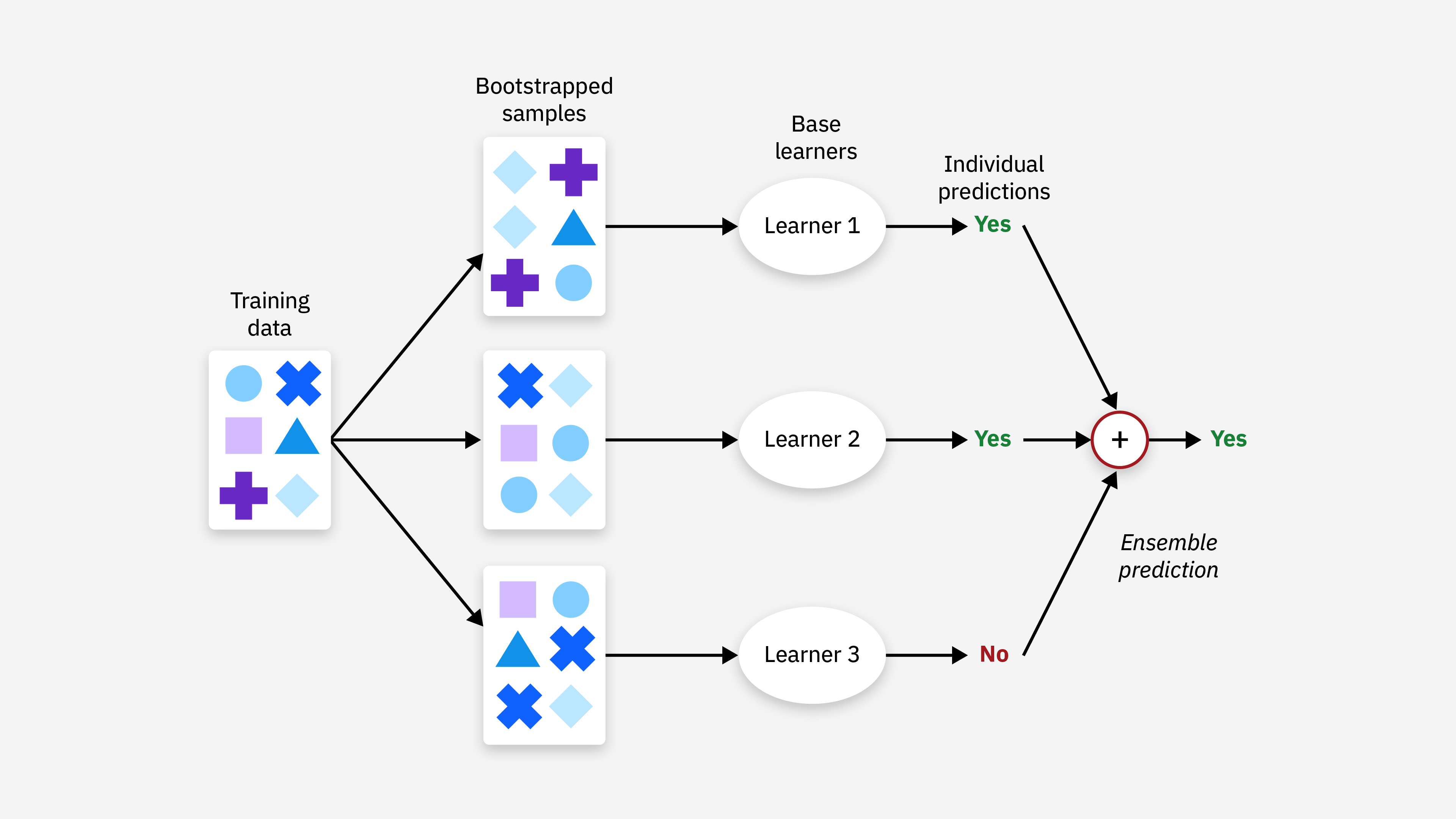
Bagging(Bootstrap Aggregating):
Bagging是一種並行集成方法,通過從訓練資料中有放回抽樣創建多個資料子集,在每個子集上訓練一個基本模型,最終結果由所有模型的預測結果投票或平均得出,減少方差,提高穩定性。
Boosting:
Boosting是一種序列化集成方法,通過迭代訓練一系列弱學習器,每個新學習器關注前面模型表現不佳的樣本,最終模型是所有弱學習器的加權組合,減少偏差,提高預測能力。
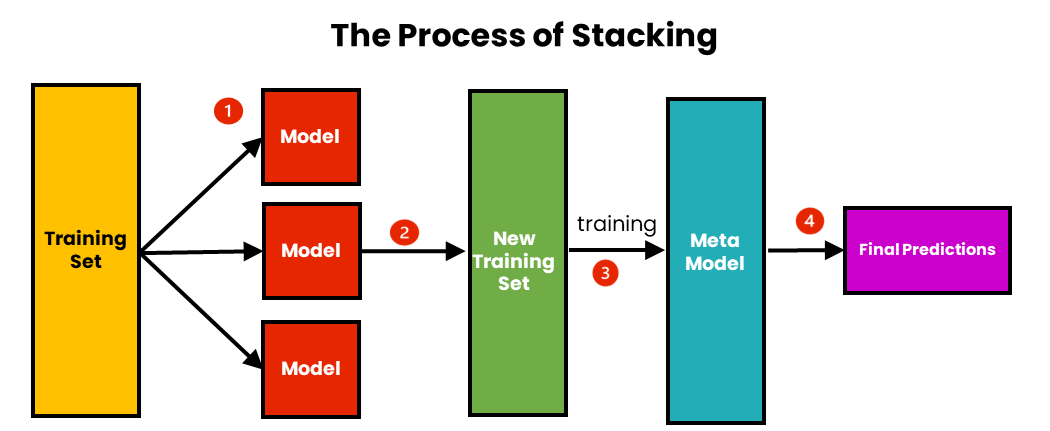
Stacking:
Stacking是一種多層集成方法,使用多個不同類型的基本模型(第一層)生成預測,然後將這些預測作為特徵訓練元模型(第二層),可以捕捉不同模型的優勢,進一步提高性能。