iPAS AI 應用規劃師
產發署50題
#1
★★★
在以下提供的選項中,請仔細考慮並指出哪一個選項不屬於監督式學習的範疇?
答案解析
監督式學習 (Supervised Learning) 的核心特徵是使用帶有標籤(即正確答案或目標輸出)的資料來訓練模型。模型學習輸入特徵與輸出標籤之間的對應關係。
(A) 回歸分析 (Regression Analysis) 是預測連續數值(如房價、溫度)的監督式學習任務。
(B) 分類技術 (Classification Techniques) 是將資料點分配到預定義的離散類別(如垃圾郵件/非垃圾郵件、貓/狗)的監督式學習任務。
(C) K-means 聚類演算法 (K-means Clustering Algorithm) 是一種典型的非監督式學習 (Unsupervised Learning) 方法。它在沒有標籤的資料中尋找資料點的自然分組(簇),目的是最小化簇內資料點的變異性。
(D) 降維技術 (Dimensionality Reduction Techniques),例如主成分分析 (PCA, Principal Component Analysis),可以是非監督式的,但也有一些監督式的降維方法(如 LDA, Linear Discriminant Analysis)。然而,K-means 明確屬於非監督式學習。因此,選項 C 是唯一明確不屬於監督式學習範疇的選項。
(A) 回歸分析 (Regression Analysis) 是預測連續數值(如房價、溫度)的監督式學習任務。
(B) 分類技術 (Classification Techniques) 是將資料點分配到預定義的離散類別(如垃圾郵件/非垃圾郵件、貓/狗)的監督式學習任務。
(C) K-means 聚類演算法 (K-means Clustering Algorithm) 是一種典型的非監督式學習 (Unsupervised Learning) 方法。它在沒有標籤的資料中尋找資料點的自然分組(簇),目的是最小化簇內資料點的變異性。
(D) 降維技術 (Dimensionality Reduction Techniques),例如主成分分析 (PCA, Principal Component Analysis),可以是非監督式的,但也有一些監督式的降維方法(如 LDA, Linear Discriminant Analysis)。然而,K-means 明確屬於非監督式學習。因此,選項 C 是唯一明確不屬於監督式學習範疇的選項。
#2
★★★
在機器學習的過程中,通常使用哪一種資料集來評估和測試模型的整體效能和準確性?
答案解析
在機器學習 (ML, Machine Learning) 中,資料集通常被劃分為三個部分:
1. 訓練集 (Training Set):用於訓練模型,讓模型學習資料中的模式和參數。
2. 驗證集 (Validation Set):用於在模型訓練過程中調整超參數 (Hyperparameters)(例如學習率、神經網路層數)以及進行模型選擇,以避免在測試集上過度擬合。
3. 測試集 (Test Set):用於在模型最終訓練完成後,評估模型在從未見過的全新資料上的泛化能力 (Generalization Ability) 和最終效能。這個評估結果是用來衡量模型實際應用效果的指標。
開發集 (Development Set) 有時與驗證集同義。因此,專門用於評估最終模型整體效能和準確性的是測試集。
1. 訓練集 (Training Set):用於訓練模型,讓模型學習資料中的模式和參數。
2. 驗證集 (Validation Set):用於在模型訓練過程中調整超參數 (Hyperparameters)(例如學習率、神經網路層數)以及進行模型選擇,以避免在測試集上過度擬合。
3. 測試集 (Test Set):用於在模型最終訓練完成後,評估模型在從未見過的全新資料上的泛化能力 (Generalization Ability) 和最終效能。這個評估結果是用來衡量模型實際應用效果的指標。
開發集 (Development Set) 有時與驗證集同義。因此,專門用於評估最終模型整體效能和準確性的是測試集。
#3
★★★
在機器學習領域中,以下哪一種演算法被歸類為非監督式學習方法?
答案解析
非監督式學習 (Unsupervised Learning) 的主要目標是在沒有標籤的資料中發現隱藏的模式或結構。
(A) 支持向量機 (SVM, Support Vector Machine) 是一種監督式學習演算法。
(B) K-means 聚類演算法 (K-means Clustering Algorithm) 將資料點分組成 K 個簇,使得每個資料點都屬於與其最近的均值 (Mean) 或中心點 (Centroid) 所對應的簇。這個過程不需要預先知道資料的類別標籤,因此是非監督式學習。
(C) 線性回歸 (Linear Regression) 是一種監督式學習演算法。
(D) 決策樹 (Decision Tree) 通常用於監督式學習(分類或回歸)。
(A) 支持向量機 (SVM, Support Vector Machine) 是一種監督式學習演算法。
(B) K-means 聚類演算法 (K-means Clustering Algorithm) 將資料點分組成 K 個簇,使得每個資料點都屬於與其最近的均值 (Mean) 或中心點 (Centroid) 所對應的簇。這個過程不需要預先知道資料的類別標籤,因此是非監督式學習。
(C) 線性回歸 (Linear Regression) 是一種監督式學習演算法。
(D) 決策樹 (Decision Tree) 通常用於監督式學習(分類或回歸)。
#4
★★★
在決策樹演算法的應用中,通常使用哪一種指標來選擇最適合的分裂點,以便有效地劃分數據?
答案解析
在構建決策樹 (Decision Tree) 時,特別是分類樹 (Classification Tree),目標是在每個節點選擇一個最佳的特徵和分裂點 (Split Point) 來劃分資料,使得劃分後的子集盡可能地「純粹」(即包含的類別盡量單一)。常用的衡量純度或不確定性的指標包括:
1. 資訊增益 (Information Gain):基於熵 (Entropy) 計算,選擇能最大程度減少熵(增加資訊量)的分裂。熵衡量的是數據集的不確定性。
2. 資訊增益率 (Gain Ratio):對資訊增益進行修正,以避免偏向具有較多取值的特徵。
3. 基尼不純度 (Gini Impurity):衡量隨機選取的樣本被錯誤分類的機率。
因此,熵是直接相關的指標,用於計算資訊增益來選擇分裂點。
(A) 平均絕對誤差 (MAE, Mean Absolute Error) 和 (C) 均方誤差 (MSE, Mean Squared Error) 主要用於回歸樹 (Regression Tree) 的分裂標準或效能評估。
(D) 精確度 (Accuracy) 是分類模型的效能評估指標,通常不用於選擇分裂點。
1. 資訊增益 (Information Gain):基於熵 (Entropy) 計算,選擇能最大程度減少熵(增加資訊量)的分裂。熵衡量的是數據集的不確定性。
2. 資訊增益率 (Gain Ratio):對資訊增益進行修正,以避免偏向具有較多取值的特徵。
3. 基尼不純度 (Gini Impurity):衡量隨機選取的樣本被錯誤分類的機率。
因此,熵是直接相關的指標,用於計算資訊增益來選擇分裂點。
(A) 平均絕對誤差 (MAE, Mean Absolute Error) 和 (C) 均方誤差 (MSE, Mean Squared Error) 主要用於回歸樹 (Regression Tree) 的分裂標準或效能評估。
(D) 精確度 (Accuracy) 是分類模型的效能評估指標,通常不用於選擇分裂點。
#5
★★★
交叉驗證技術在機器學習中主要用來達成什麼目的,以確保模型的泛化能力?
答案解析
交叉驗證 (Cross-validation) 是一種模型評估技術,尤其在資料集有限的情況下很有用。它將原始訓練集分成 K 個子集(K-折交叉驗證, K-Fold Cross-validation),然後進行 K 次訓練和驗證:每次使用 K-1 個子集進行訓練,剩下的 1 個子集進行驗證。最終將 K 次的驗證結果平均,得到一個更穩健的模型效能評估。
其主要目的包括:
1. 更可靠地評估模型的泛化能力 (Generalization Ability),即模型在未見過數據上的表現。
2. 幫助檢測和避免過度擬合 (Overfitting),因為如果模型在訓練集上表現很好但在驗證集上表現差,則可能存在過度擬合。
3. 用於模型選擇和超參數調整 (Hyperparameter Tuning)。
(B) 它不增加資料集大小。(C) 它通常會增加總訓練時間。(D) 其目的是評估和控制複雜度,而不是盲目提升複雜度。因此,選項 A 最能描述交叉驗證的主要目的。
其主要目的包括:
1. 更可靠地評估模型的泛化能力 (Generalization Ability),即模型在未見過數據上的表現。
2. 幫助檢測和避免過度擬合 (Overfitting),因為如果模型在訓練集上表現很好但在驗證集上表現差,則可能存在過度擬合。
3. 用於模型選擇和超參數調整 (Hyperparameter Tuning)。
(B) 它不增加資料集大小。(C) 它通常會增加總訓練時間。(D) 其目的是評估和控制複雜度,而不是盲目提升複雜度。因此,選項 A 最能描述交叉驗證的主要目的。
#6
★★★
支持向量機(SVM)在機器學習中的主要目的是什麼,特別是在處理 分類和回歸問題時?
答案解析
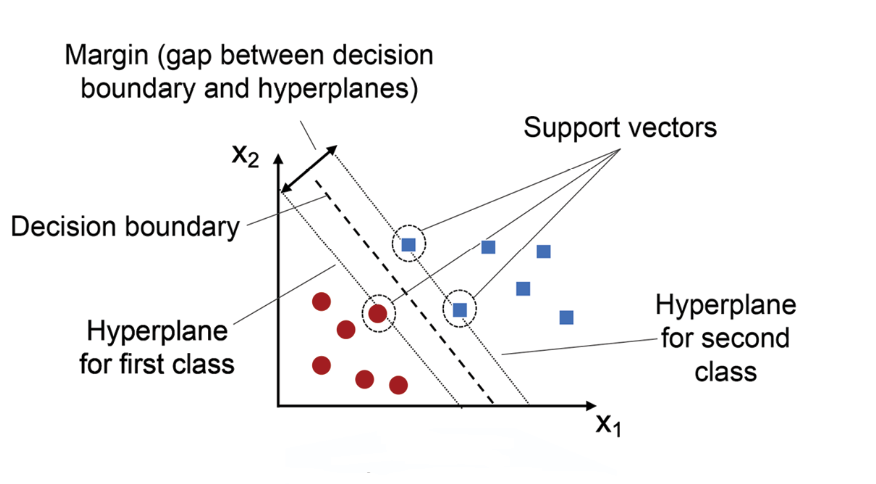
支持向量機 (SVM, Support Vector Machine) 是一種強大的監督式學習模型。
- 在分類 (Classification) 問題中,SVM 的目標是找到一個能夠將不同類別的資料點分開的最佳超平面 (Hyperplane)。這個「最佳」通常指間隔 (Margin) 最大化,即超平面與最接近的任一類別的資料點(稱為支持向量, Support Vectors)之間的距離最大化,這有助於提高模型的泛化能力。
- SVM 也可以擴展到回歸 (Regression) 問題,稱為支持向量回歸 (SVR, Support Vector Regression),其目標是找到一個超平面,使得盡可能多的資料點落在間隔帶 (Margin Band) 內,同時最小化超出間隔帶的誤差。
(A) SVM 不是生成模型。(C) SVM 利用特徵進行分類/回歸,但不直接進行特徵提取。(D) 聚類是非監督式學習的任務。因此,選項 B 最準確地描述了 SVM 的核心目的。
- 在分類 (Classification) 問題中,SVM 的目標是找到一個能夠將不同類別的資料點分開的最佳超平面 (Hyperplane)。這個「最佳」通常指間隔 (Margin) 最大化,即超平面與最接近的任一類別的資料點(稱為支持向量, Support Vectors)之間的距離最大化,這有助於提高模型的泛化能力。
- SVM 也可以擴展到回歸 (Regression) 問題,稱為支持向量回歸 (SVR, Support Vector Regression),其目標是找到一個超平面,使得盡可能多的資料點落在間隔帶 (Margin Band) 內,同時最小化超出間隔帶的誤差。
(A) SVM 不是生成模型。(C) SVM 利用特徵進行分類/回歸,但不直接進行特徵提取。(D) 聚類是非監督式學習的任務。因此,選項 B 最準確地描述了 SVM 的核心目的。
#7
★★★
在處理高維數據時,以下哪一種方法通常被用來減少特徵數量,從而 簡化模型並提高計算效率?
答案解析
處理高維數據 (High-dimensional Data) 時,可能會遇到「維度災難」(Curse of Dimensionality) 問題,導致模型訓練困難、計算成本高且容易過度擬合。降維 (Dimensionality Reduction) 技術旨在減少資料的特徵數量(維度),同時盡可能保留重要資訊。
(A) 主成分分析 (PCA, Principal Component Analysis) 是一種非常流行的非監督式降維方法,它通過線性變換找到資料變異數最大的方向(主成分),將資料投影到這些方向上,從而達到降維的目的。
(B) 決策樹 (Decision Tree)、(C) K 最近鄰 (KNN, K-Nearest Neighbors) 和 (D) 隨機森林 (Random Forest) 都是監督式學習模型,主要用於分類或回歸,而不是直接用於降維(儘管某些方法如隨機森林可以評估特徵重要性,間接輔助降維)。因此,PCA 是最直接用於降維的技術。
(A) 主成分分析 (PCA, Principal Component Analysis) 是一種非常流行的非監督式降維方法,它通過線性變換找到資料變異數最大的方向(主成分),將資料投影到這些方向上,從而達到降維的目的。
(B) 決策樹 (Decision Tree)、(C) K 最近鄰 (KNN, K-Nearest Neighbors) 和 (D) 隨機森林 (Random Forest) 都是監督式學習模型,主要用於分類或回歸,而不是直接用於降維(儘管某些方法如隨機森林可以評估特徵重要性,間接輔助降維)。因此,PCA 是最直接用於降維的技術。
#8
★★★
隨機森林演算法在機器學習中屬於哪一類型的演算法,其主要特點是結合 多個基礎模型以提升整體效能?
答案解析
集成學習 (Ensemble Learning) 是一種機器學習策略,它通過構建並結合多個學習器(或稱基礎模型、弱學習器)來完成學習任務,以獲得比單個學習器更好的預測效能。隨機森林 (Random Forest) 是集成學習中 Bagging (Bootstrap Aggregating) 方法的一個擴展變體。
隨機森林構建多個決策樹,每棵樹在訓練時使用隨機抽樣的資料子集(Bootstrap Sampling)和隨機選取的特徵子集。最終的預測結果由所有決策樹的預測結果通過投票(分類)或平均(回歸)來決定。這種集成方式可以有效降低模型的變異數 (Variance) 並提高泛化能力。
(A) 聚類是非監督式學習。(C) 強化學習是通過獎勵學習策略。(D) 降維是減少特徵維度。因此,隨機森林屬於集成學習方法。
隨機森林構建多個決策樹,每棵樹在訓練時使用隨機抽樣的資料子集(Bootstrap Sampling)和隨機選取的特徵子集。最終的預測結果由所有決策樹的預測結果通過投票(分類)或平均(回歸)來決定。這種集成方式可以有效降低模型的變異數 (Variance) 並提高泛化能力。
(A) 聚類是非監督式學習。(C) 強化學習是通過獎勵學習策略。(D) 降維是減少特徵維度。因此,隨機森林屬於集成學習方法。
#9
★★★
在機器學習中,L1 正則化技術主要用於達成什麼目的,以防止模型 的過度擬合?
答案解析
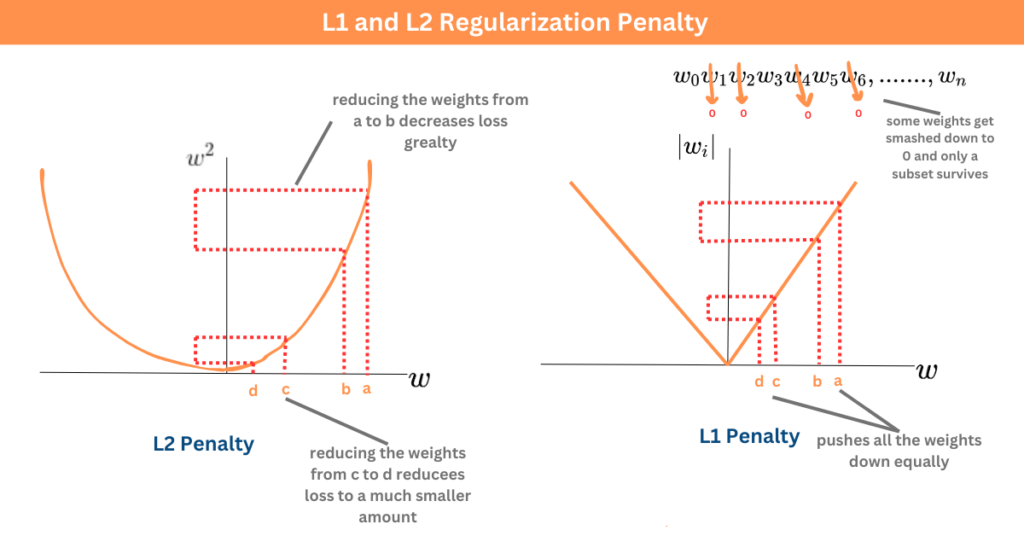
正則化 (Regularization) 是一種在機器學習中用於防止過度擬合 (Overfitting) 的技術,它通過向模型的損失函數 (Loss Function) 中添加一個懲罰項 (Penalty Term) 來限制模型的複雜度。
L1 正則化(又稱 Lasso 回歸, Lasso Regression)添加的懲罰項是模型權重 (Weights) 的絕對值之和(L1 範數, L1 Norm)。這種懲罰方式有兩個主要效果:
1. 懲罰過大的權重:迫使模型學習較小的權重,降低模型的複雜度。
2. 產生稀疏權重:傾向於將一些不重要的特徵的權重壓縮到恰好為零,從而實現自動的特徵選擇 (Feature Selection)。
這兩個效果都有助於減少模型的過度擬合風險,提高模型的泛化能力。
(A) L1 正則化是降低複雜度。(C) 它與訓練數據數量無直接關係。(D) 它可能通過特徵選擇簡化模型,但不直接增強特徵提取。因此,選項 B 是其主要目的。
L1 正則化(又稱 Lasso 回歸, Lasso Regression)添加的懲罰項是模型權重 (Weights) 的絕對值之和(L1 範數, L1 Norm)。這種懲罰方式有兩個主要效果:
1. 懲罰過大的權重:迫使模型學習較小的權重,降低模型的複雜度。
2. 產生稀疏權重:傾向於將一些不重要的特徵的權重壓縮到恰好為零,從而實現自動的特徵選擇 (Feature Selection)。
這兩個效果都有助於減少模型的過度擬合風險,提高模型的泛化能力。
(A) L1 正則化是降低複雜度。(C) 它與訓練數據數量無直接關係。(D) 它可能通過特徵選擇簡化模型,但不直接增強特徵提取。因此,選項 B 是其主要目的。
#10
★★★
強化學習領域中,主要的策略目標是什麼,以指導智能體在環境 中做出最佳行動決策?
答案解析
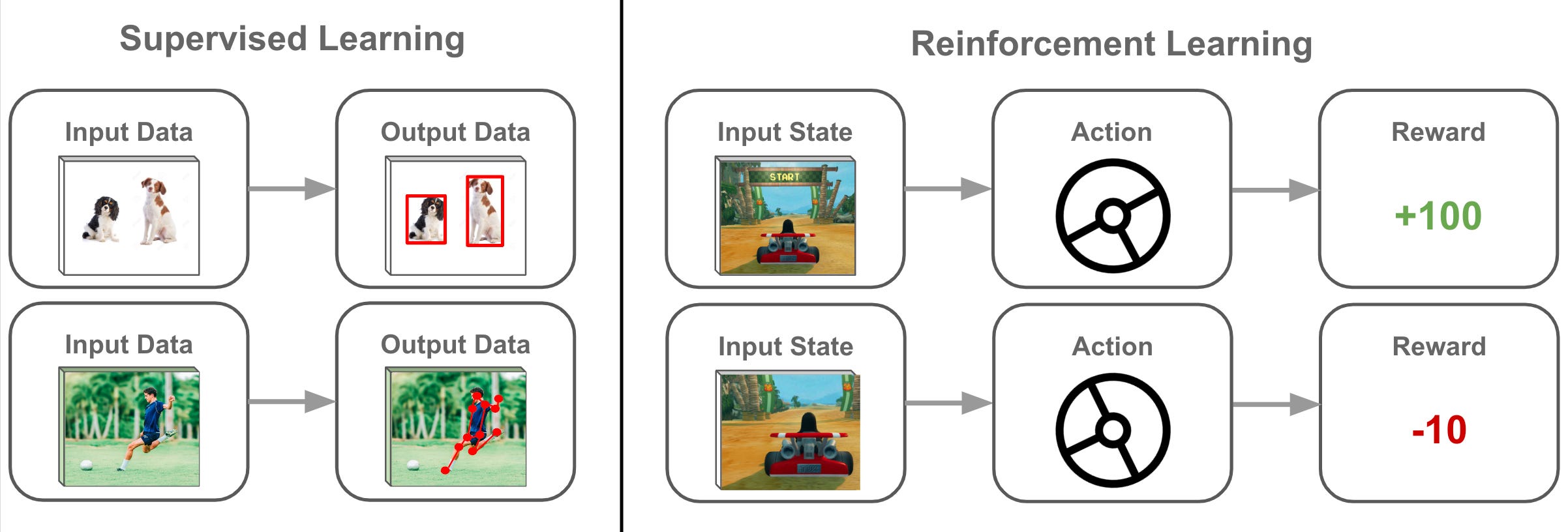
強化學習 (RL, Reinforcement Learning) 是一種機器學習範式,其中智能體 (Agent) 通過與環境 (Environment) 互動來學習。 智能體執行動作 (Action),觀察環境的狀態 (State) 變化,並獲得獎勵 (Reward) 或懲罰 (Penalty) 信號。
強化學習的最終目標是學習一個策略 (Policy),即在給定狀態下選擇哪個動作的規則,使得智能體能夠獲得的長期累積獎勵總和(通常是帶有折扣因子的未來獎勵之和)最大化。因此,獎勵最大化 (Reward Maximization) 是 RL 的核心目標。
(A) 隨機搜索可用於探索,但不是最終目標。(B) 誤差反向傳播 (Backpropagation) 是監督學習中訓練神經網路的方法。(D) RL 通常不依賴標註數據,而是通過獎勵信號學習。
強化學習的最終目標是學習一個策略 (Policy),即在給定狀態下選擇哪個動作的規則,使得智能體能夠獲得的長期累積獎勵總和(通常是帶有折扣因子的未來獎勵之和)最大化。因此,獎勵最大化 (Reward Maximization) 是 RL 的核心目標。
(A) 隨機搜索可用於探索,但不是最終目標。(B) 誤差反向傳播 (Backpropagation) 是監督學習中訓練神經網路的方法。(D) RL 通常不依賴標註數據,而是通過獎勵信號學習。
#11
★★★
在機器學習的應用中,以下哪一種方法主要用於處理分類問題,特別 是在將數據分配到不同類別的過程中?
答案解析
分類 (Classification) 是機器學習中監督式學習的一項核心任務,目標是將輸入的數據實例分配到預先定義好的離散類別中。
(A) 回歸分析 (Regression Analysis) 用於預測連續值,不是分類。
(B) 聚類分析 (Clustering Analysis) 是非監督式學習,用於發現數據中的分組,沒有預定義的類別。
(C) 支持向量機 (SVM, Support Vector Machine) 是一種非常有效的分類演算法,它尋找能夠最好地區分不同類別的決策邊界 (Decision Boundary) 或超平面 (Hyperplane)。雖然它也能用於回歸,但其在分類任務中尤為著名和常用。
(D) 主成分分析 (PCA, Principal Component Analysis) 主要用於降維,減少數據的特徵數量。
(A) 回歸分析 (Regression Analysis) 用於預測連續值,不是分類。
(B) 聚類分析 (Clustering Analysis) 是非監督式學習,用於發現數據中的分組,沒有預定義的類別。
(C) 支持向量機 (SVM, Support Vector Machine) 是一種非常有效的分類演算法,它尋找能夠最好地區分不同類別的決策邊界 (Decision Boundary) 或超平面 (Hyperplane)。雖然它也能用於回歸,但其在分類任務中尤為著名和常用。
(D) 主成分分析 (PCA, Principal Component Analysis) 主要用於降維,減少數據的特徵數量。
#12
★★★
在機器學習的訓練過程中,以下哪一種方法主要用於減少模型過度擬合的風險,通過對模型的複雜度進行懲罰來提升模型的泛化能力?
答案解析
過度擬合 (Overfitting) 指的是機器學習模型在訓練集上表現過好,但對未見過的新數據(測試集)表現較差的現象,即模型的泛化能力 (Generalization Ability) 不足。這通常發生在模型過於複雜,學習到了訓練集中的雜訊或特定模式時。
(A) 正則化 (Regularization) 技術(如 L1、L2 正則化)通過在模型的損失函數中增加一個對模型參數(權重)大小的懲罰項,來限制模型的複雜度,從而降低過度擬合的風險。
(B) 遺傳演算法 (Genetic Algorithm) 是一種優化演算法,可用於模型訓練或超參數搜索,但本身不是直接針對過度擬合的技術。
(C) 貝氏網路 (Bayesian Network) 是一種機率圖模型,用於表示變數間的依賴關係,其本身與過度擬合控制無直接關係,但模型選擇時可能考慮複雜度。
(D) K 最近鄰 (KNN, K-Nearest Neighbors) 是一種基於實例的學習演算法,其複雜度與 K 值有關,但正則化是更通用的控制模型複雜度、防止過度擬合的策略。
(A) 正則化 (Regularization) 技術(如 L1、L2 正則化)通過在模型的損失函數中增加一個對模型參數(權重)大小的懲罰項,來限制模型的複雜度,從而降低過度擬合的風險。
(B) 遺傳演算法 (Genetic Algorithm) 是一種優化演算法,可用於模型訓練或超參數搜索,但本身不是直接針對過度擬合的技術。
(C) 貝氏網路 (Bayesian Network) 是一種機率圖模型,用於表示變數間的依賴關係,其本身與過度擬合控制無直接關係,但模型選擇時可能考慮複雜度。
(D) K 最近鄰 (KNN, K-Nearest Neighbors) 是一種基於實例的學習演算法,其複雜度與 K 值有關,但正則化是更通用的控制模型複雜度、防止過度擬合的策略。
#13
★★★
在機器學習的範疇中,以下哪一種方法被歸類為非監督式學習的例 子,特別是在未使用標註數據的情況下進行數據聚類?
答案解析
非監督式學習 (Unsupervised Learning) 處理的是未標註的數據,其目標是從數據中發現結構、模式或關係。數據聚類 (Data Clustering) 是非監督式學習的一個主要應用,旨在將相似的數據點分到同一個簇 (Cluster) 中。
(A) 決策樹 (Decision Tree)、(C) 線性回歸 (Linear Regression) 和 (D) 邏輯回歸 (Logistic Regression) 都是典型的監督式學習演算法,需要帶有標籤的數據進行訓練。
(B) K-means 聚類演算法 (K-means Clustering Algorithm) 根據數據點之間的距離將其分組,無需預先知道類別標籤,是非監督式學習中聚類任務的代表性演算法。
(A) 決策樹 (Decision Tree)、(C) 線性回歸 (Linear Regression) 和 (D) 邏輯回歸 (Logistic Regression) 都是典型的監督式學習演算法,需要帶有標籤的數據進行訓練。
(B) K-means 聚類演算法 (K-means Clustering Algorithm) 根據數據點之間的距離將其分組,無需預先知道類別標籤,是非監督式學習中聚類任務的代表性演算法。
#14
★★★
在影像處理的領域中,以下哪一種演算法主要用於檢測圖像中的邊緣,從而識別物體的輪廓?
答案解析
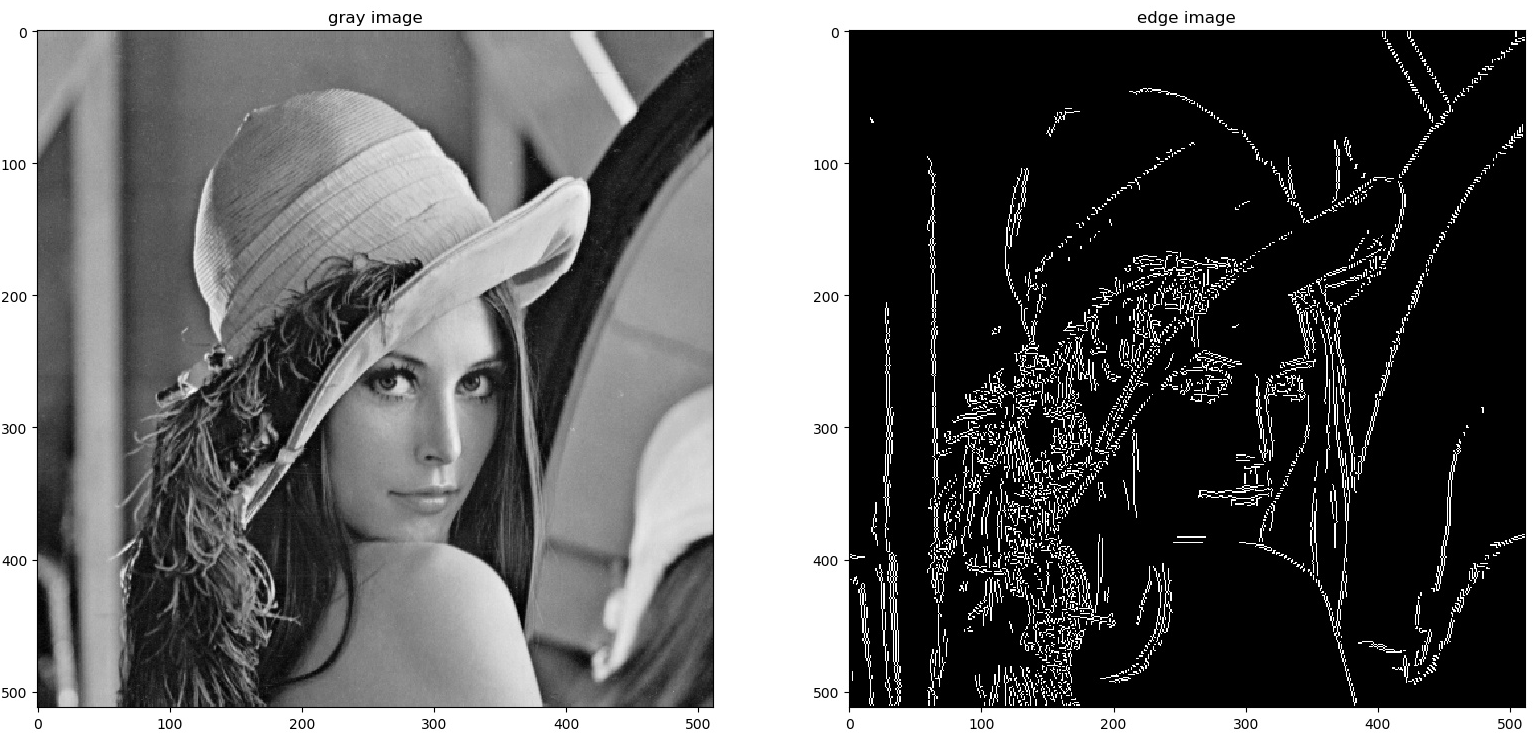
邊緣檢測 (Edge Detection) 是影像處理 (Image Processing) 和電腦視覺 (CV, Computer Vision) 中的一項基本任務,旨在識別圖像中亮度(或顏色)發生顯著變化的點集,這些點通常構成物體的邊界或輪廓。
(A) K-means 可用於影像分割,但不是專門的邊緣檢測演算法。
(B) Canny 邊緣檢測演算法 (Canny Edge Detection Algorithm) 是一種多階段的優化邊緣檢測方法,以其良好的檢測效果(低錯誤率、精確定位、單一響應)而聞名,是邊緣檢測領域的經典演算法。
(C) PCA 用於降維。
(D) SVM 用於分類。
(A) K-means 可用於影像分割,但不是專門的邊緣檢測演算法。
(B) Canny 邊緣檢測演算法 (Canny Edge Detection Algorithm) 是一種多階段的優化邊緣檢測方法,以其良好的檢測效果(低錯誤率、精確定位、單一響應)而聞名,是邊緣檢測領域的經典演算法。
(C) PCA 用於降維。
(D) SVM 用於分類。
#15
★★★
在影像分類的應用中,以下哪一種神經網路的縮寫代表了專門用於 處理影像數據的卷積神經網路?
答案解析
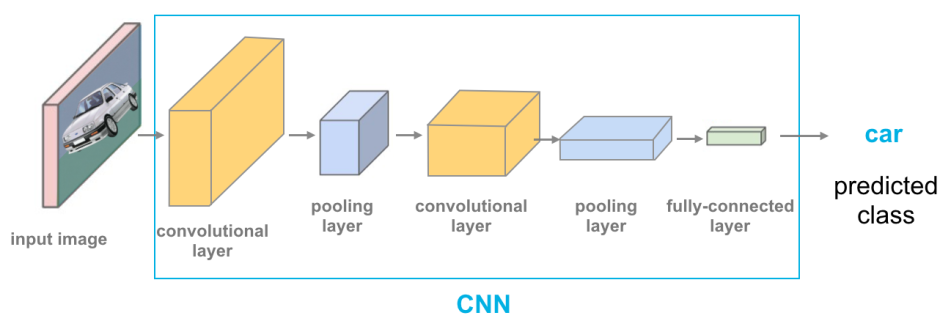
卷積神經網路 (CNN, Convolutional Neural Network) 是深度學習 (DL, Deep Learning) 中專門設計來處理具有網格狀拓撲結構數據(如影像數據, Image Data,可以看作是像素的二維網格)的一類神經網路 (Neural Network)。
CNN 的核心是卷積層 (Convolutional Layer) 和池化層 (Pooling Layer),這些層能夠有效地捕捉影像的空間層次結構特徵(如邊緣、紋理、物體部件),使其在影像分類 (Image Classification)、物體檢測 (Object Detection) 等電腦視覺任務中表現非常出色。
(A) 循環神經網路 (RNN, Recurrent Neural Network) 和 (C) 長短期記憶網路 (LSTM, Long Short-Term Memory) 主要用於處理序列數據(如文本、時間序列)。
(D) 生成對抗網路 (GAN, Generative Adversarial Network) 是一種生成模型,常用於生成新的影像等數據。
CNN 的核心是卷積層 (Convolutional Layer) 和池化層 (Pooling Layer),這些層能夠有效地捕捉影像的空間層次結構特徵(如邊緣、紋理、物體部件),使其在影像分類 (Image Classification)、物體檢測 (Object Detection) 等電腦視覺任務中表現非常出色。
(A) 循環神經網路 (RNN, Recurrent Neural Network) 和 (C) 長短期記憶網路 (LSTM, Long Short-Term Memory) 主要用於處理序列數據(如文本、時間序列)。
(D) 生成對抗網路 (GAN, Generative Adversarial Network) 是一種生成模型,常用於生成新的影像等數據。
#16
★★★
在電腦視覺的應用中,影像分割技術的主要目的是什麼,特別是在 將影像拆分成不同區域的過程中?
答案解析
影像分割 (Image Segmentation) 是電腦視覺 (CV, Computer Vision) 中的一項關鍵任務,其目標是將數位影像劃分成多個影像片段 (Segments) 或區域 (Regions),使得每個片段對應於影像中的某個特定物體或有意義的部分。換句話說,它試圖在像素層級上理解影像,為影像中的每個像素分配一個標籤,指示該像素屬於哪個物體或區域。
與影像分類(對整個影像進行分類)和物體檢測(標出物體位置的邊界框)相比,影像分割提供了更精細的影像理解。
(A) 邊緣檢測是識別邊緣,是分割的基礎之一,但不是最終目的。(B) 特徵提取是分割等任務的中間步驟。(D) 降噪是影像預處理。因此,選項 C 最能描述影像分割的目的。
與影像分類(對整個影像進行分類)和物體檢測(標出物體位置的邊界框)相比,影像分割提供了更精細的影像理解。
(A) 邊緣檢測是識別邊緣,是分割的基礎之一,但不是最終目的。(B) 特徵提取是分割等任務的中間步驟。(D) 降噪是影像預處理。因此,選項 C 最能描述影像分割的目的。
#17
★★★
影像增強技術中,以下哪一種方法不屬於影像增強的範疇,並且 主要用於數據降維?
答案解析
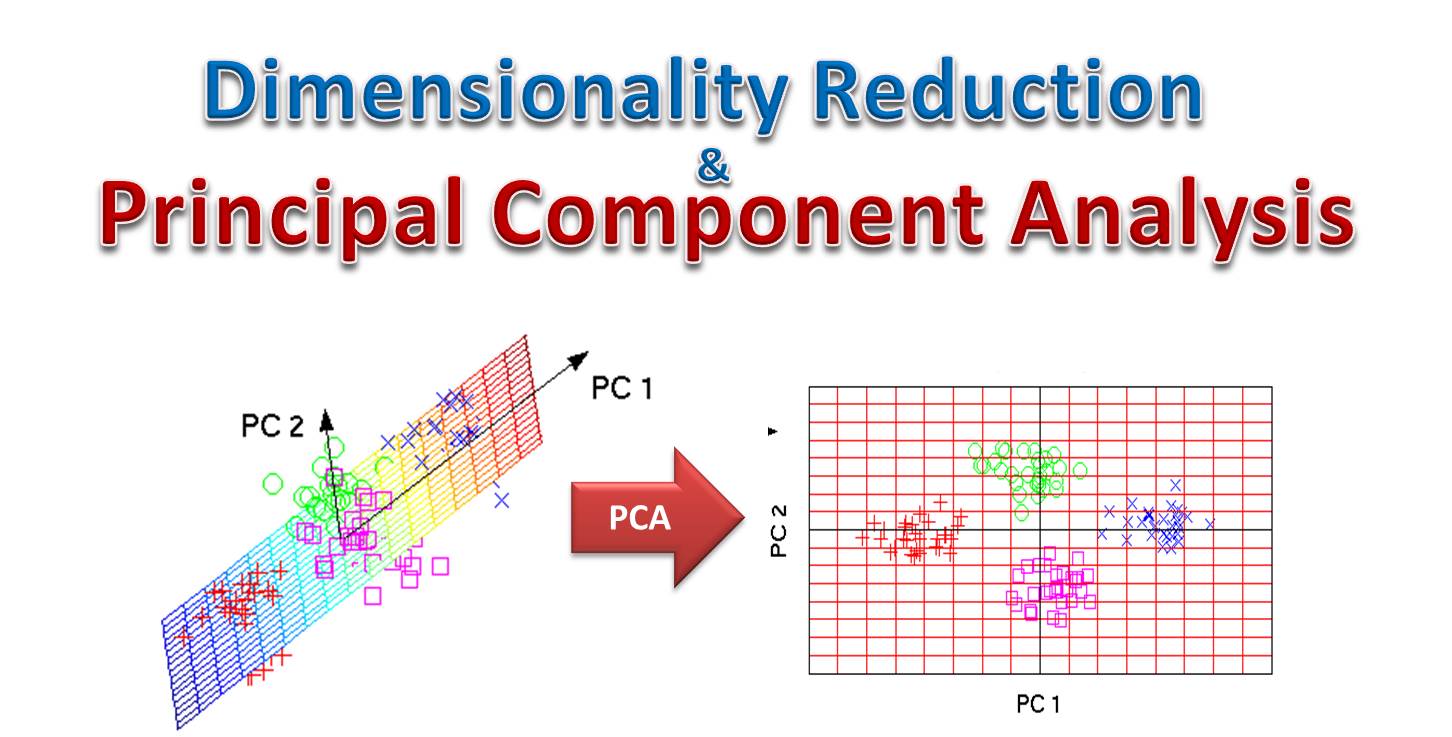
影像增強 (Image Enhancement) 的目的是改善影像的視覺品質或突顯影像中的某些感興趣的資訊,以便於人類觀察或後續的機器分析。
(A) 直方圖均衡化 (Histogram Equalization) 通過重新分佈影像的像素強度來提高影像的全局對比度,屬於影像增強。
(B) 高斯模糊 (Gaussian Blur) 是一種影像平滑技術,常用於降噪,廣義上也屬於影像處理(有時也視為影像增強的一種預處理)。
(D) 形態學變換 (Morphological Transformations),如膨脹 (Dilation)、腐蝕 (Erosion) 等,用於分析和處理影像的幾何結構(形狀),可應用於降噪、分割預處理等,屬於影像處理範疇。
(C) 主成分分析 (PCA, Principal Component Analysis) 是一種統計學方法,主要用於降維 (Dimensionality Reduction),即減少數據集的變數(特徵)數量,同時盡量保留原始數據的變異性。它不屬於典型的影像增強技術。
(A) 直方圖均衡化 (Histogram Equalization) 通過重新分佈影像的像素強度來提高影像的全局對比度,屬於影像增強。
(B) 高斯模糊 (Gaussian Blur) 是一種影像平滑技術,常用於降噪,廣義上也屬於影像處理(有時也視為影像增強的一種預處理)。
(D) 形態學變換 (Morphological Transformations),如膨脹 (Dilation)、腐蝕 (Erosion) 等,用於分析和處理影像的幾何結構(形狀),可應用於降噪、分割預處理等,屬於影像處理範疇。
(C) 主成分分析 (PCA, Principal Component Analysis) 是一種統計學方法,主要用於降維 (Dimensionality Reduction),即減少數據集的變數(特徵)數量,同時盡量保留原始數據的變異性。它不屬於典型的影像增強技術。
#18
★★★
在影像處理的過程中,通常使用哪一種技術來去除影像中的雜訊, 從而改善影像的質量?
答案解析
影像降噪 (Image Denoising) 是影像處理中的一個重要環節,目的是去除或減少影像採集或傳輸過程中引入的雜訊 (Noise),以恢復原始影像的資訊或改善視覺品質。
(B) 濾波技術 (Filtering Techniques) 是實現影像降噪的主要手段。根據雜訊的類型和特性,可以選用不同的濾波器,例如:
- 均值濾波器 (Mean Filter) 和 高斯濾波器 (Gaussian Filter) 對於去除高斯雜訊效果較好,但會使影像模糊。
- 中值濾波器 (Median Filter) 對於去除椒鹽雜訊 (Salt-and-pepper Noise) 效果較好,且能較好地保留邊緣資訊。
(A) 邊緣檢測的目的是找邊緣。(C) 形態學變換主要處理形狀。(D) 影像增強是更廣泛的概念,降噪可以視為其中的一步。因此,濾波技術是專門用於降噪的核心方法。
(B) 濾波技術 (Filtering Techniques) 是實現影像降噪的主要手段。根據雜訊的類型和特性,可以選用不同的濾波器,例如:
- 均值濾波器 (Mean Filter) 和 高斯濾波器 (Gaussian Filter) 對於去除高斯雜訊效果較好,但會使影像模糊。
- 中值濾波器 (Median Filter) 對於去除椒鹽雜訊 (Salt-and-pepper Noise) 效果較好,且能較好地保留邊緣資訊。
(A) 邊緣檢測的目的是找邊緣。(C) 形態學變換主要處理形狀。(D) 影像增強是更廣泛的概念,降噪可以視為其中的一步。因此,濾波技術是專門用於降噪的核心方法。
#19
★★★
在卷積神經網路(CNN)中,卷積操作的主要功能是什麼,特別是 在從影像中提取特徵的過程中?
答案解析
卷積操作 (Convolution Operation) 是卷積神經網路 (CNN, Convolutional Neural Network) 的核心運算。它通過將一個可學習的卷積核 (Convolution Kernel) 或濾波器 (Filter) 在輸入影像(或特徵圖)上滑動,並計算卷積核與其覆蓋的局部區域之間的內積 (Dot Product) 或加權和 (Weighted Sum),來生成輸出特徵圖 (Feature Map)。
這個過程的本質是特徵提取 (Feature Extraction)。每個卷積核可以被看作是一個特徵檢測器 (Feature Detector),用於檢測輸入中的特定模式,例如邊緣、角點、紋理或更複雜的形狀。通過堆疊多個卷積層,CNN 可以學習到從低級到高級的層次化特徵表示 (Hierarchical Feature Representations)。
(B) 資料標註是數據準備階段的工作。(C) 數據增強是擴充訓練集的技術。(D) 影像分割是CNN 的應用之一,但卷積操作本身的功能是特徵提取。
這個過程的本質是特徵提取 (Feature Extraction)。每個卷積核可以被看作是一個特徵檢測器 (Feature Detector),用於檢測輸入中的特定模式,例如邊緣、角點、紋理或更複雜的形狀。通過堆疊多個卷積層,CNN 可以學習到從低級到高級的層次化特徵表示 (Hierarchical Feature Representations)。
(B) 資料標註是數據準備階段的工作。(C) 數據增強是擴充訓練集的技術。(D) 影像分割是CNN 的應用之一,但卷積操作本身的功能是特徵提取。
#20
★★★
使用 R-CNN 技術在電腦視覺中的主要目的是什麼,特別是在處理 影像中的物體時?
答案解析
R-CNN (Regions with CNN features) 及其後續演進(如 Fast R-CNN, Faster R-CNN)是深度學習時代物體檢測 (Object Detection) 領域的開創性工作。物體檢測的任務不僅僅是識別影像中有哪些物體(分類),更重要的是要精確地定位出這些物體在影像中的位置,通常使用邊界框 (Bounding Box) 來表示。
R-CNN 的基本思路是:首先使用某種區域提議 (Region Proposal) 方法(如 Selective Search)生成大量可能包含物體的候選區域,然後對每個區域使用 CNN 提取特徵,最後用分類器(如 SVM)判斷區域的類別並用迴歸器 (Regressor) 修正邊界框位置。
(A) 影像分類只判斷影像內容,不定位。(C) 影像生成是創建影像。(D) 數據增強是擴充數據。因此,R-CNN 的主要目的是物體檢測。
R-CNN 的基本思路是:首先使用某種區域提議 (Region Proposal) 方法(如 Selective Search)生成大量可能包含物體的候選區域,然後對每個區域使用 CNN 提取特徵,最後用分類器(如 SVM)判斷區域的類別並用迴歸器 (Regressor) 修正邊界框位置。
(A) 影像分類只判斷影像內容,不定位。(C) 影像生成是創建影像。(D) 數據增強是擴充數據。因此,R-CNN 的主要目的是物體檢測。
#21
★★★
在電腦視覺的應用中,為了縮小影像的尺寸以減少計算量,通常會 使用哪一種方法?
答案解析
池化層 (Pooling Layer) 是卷積神經網路 (CNN) 中的常用組件,通常放置在卷積層之後。它的主要作用是對輸入的特徵圖 (Feature Map) 進行下採樣 (Downsampling),即縮小其空間尺寸(寬度和高度)。
常見的池化操作包括最大池化 (Max Pooling) 和平均池化 (Average Pooling),它們分別取局部區域內的最大值或平均值作為輸出。這樣做的好處包括:
1. 減少計算量:降低後續層的參數數量和計算複雜度。
2. 增大感受野:使後續層的神經元能看到更廣闊的輸入區域。
3. 提高穩健性:對輸入的微小平移、旋轉或變形具有一定的不變性。
(A) 決策樹是機器學習模型。(C) 過濾可用於影像增強或降噪。(D) 特徵提取是CNN 的整體目標,池化是其中的一步。因此,專門用於縮小尺寸、減少計算量的是池化層。
常見的池化操作包括最大池化 (Max Pooling) 和平均池化 (Average Pooling),它們分別取局部區域內的最大值或平均值作為輸出。這樣做的好處包括:
1. 減少計算量:降低後續層的參數數量和計算複雜度。
2. 增大感受野:使後續層的神經元能看到更廣闊的輸入區域。
3. 提高穩健性:對輸入的微小平移、旋轉或變形具有一定的不變性。
(A) 決策樹是機器學習模型。(C) 過濾可用於影像增強或降噪。(D) 特徵提取是CNN 的整體目標,池化是其中的一步。因此,專門用於縮小尺寸、減少計算量的是池化層。
#22
★★★
YOLO 演算法在電腦視覺中的主要用途是什麼,特別是在即時物體檢測方面?
答案解析
YOLO (You Only Look Once) 是一種非常流行的物體檢測 (Object Detection) 演算法,屬於一階段檢測器 (One-Stage Detector)。與 R-CNN 系列等兩階段檢測器 (Two-Stage Detector) 不同,YOLO 將物體檢測視為一個回歸問題,直接從整個輸入影像預測出所有物體的邊界框 (Bounding Boxes) 和類別機率 (Class Probabilities)。
這種端到端的設計使得 YOLO 具有非常快的檢測速度,能夠達到實時(Real-time)處理的要求,因此在需要快速響應的應用中(如自動駕駛、影片監控)得到廣泛應用。其主要用途就是進行快速且相對準確的物體檢測。
(B) 影像分割是像素級分類。(C) 特徵提取是物體檢測的基礎。(D) 影像增強是預處理。
這種端到端的設計使得 YOLO 具有非常快的檢測速度,能夠達到實時(Real-time)處理的要求,因此在需要快速響應的應用中(如自動駕駛、影片監控)得到廣泛應用。其主要用途就是進行快速且相對準確的物體檢測。
(B) 影像分割是像素級分類。(C) 特徵提取是物體檢測的基礎。(D) 影像增強是預處理。

#23
★★★
在影像處理的過程中,通常使用哪一種技術來實現影像的平滑效果,以減少影像中的雜訊和細節?
答案解析
影像平滑 (Image Smoothing) 或影像模糊 (Image Blurring) 的目的是減少影像中的雜訊 (Noise) 和不必要的細節,使影像看起來更平滑。這通常通過各種濾波 (Filtering) 技術來實現。
(A) 高斯模糊 (Gaussian Blur) 是一種常用的線性平滑技術。它使用一個高斯濾波器(其權重由高斯函數決定)對影像進行卷積,相當於對每個像素計算其鄰域像素的加權平均值,權重隨距離中心像素的遠近呈高斯分佈。這能有效抑制高斯雜訊並產生平滑效果。
(B) 邊緣檢測是尋找影像強度變化劇烈的地方。(C) PCA 用於降維。(D) 決策樹是機器學習模型。因此,高斯模糊是實現平滑效果的代表性技術。
(A) 高斯模糊 (Gaussian Blur) 是一種常用的線性平滑技術。它使用一個高斯濾波器(其權重由高斯函數決定)對影像進行卷積,相當於對每個像素計算其鄰域像素的加權平均值,權重隨距離中心像素的遠近呈高斯分佈。這能有效抑制高斯雜訊並產生平滑效果。
(B) 邊緣檢測是尋找影像強度變化劇烈的地方。(C) PCA 用於降維。(D) 決策樹是機器學習模型。因此,高斯模糊是實現平滑效果的代表性技術。

#24
★★★
在電腦視覺的應用中,以下哪一種技術主要用於物體檢測,特別是 在即時識別和定位影像中的物體方面?
答案解析
物體檢測 (Object Detection) 是電腦視覺 (CV, Computer Vision) 的核心任務之一,目標是識別影像中的物體並確定它們的位置(通常用邊界框標示)。
(A) 卷積神經網路 (CNN, Convolutional Neural Network) 是現代物體檢測演算法的基石。無論是 R-CNN 系列、YOLO、SSD (Single Shot MultiBox Detector) 等主流物體檢測框架,都依賴 CNN 作為其骨幹網路 (Backbone Network) 來提取影像的強大視覺特徵 (Visual Features)。這些特徵包含了識別和定位物體所需的關鍵資訊。
(B) LSTM 主要處理時序或序列資訊。(C) 自然語言處理 (NLP, Natural Language Processing) 處理文本。(D) 強化學習 (RL, Reinforcement Learning) 主要用於決策制定。因此,CNN 是物體檢測最核心的技術基礎。
(A) 卷積神經網路 (CNN, Convolutional Neural Network) 是現代物體檢測演算法的基石。無論是 R-CNN 系列、YOLO、SSD (Single Shot MultiBox Detector) 等主流物體檢測框架,都依賴 CNN 作為其骨幹網路 (Backbone Network) 來提取影像的強大視覺特徵 (Visual Features)。這些特徵包含了識別和定位物體所需的關鍵資訊。
(B) LSTM 主要處理時序或序列資訊。(C) 自然語言處理 (NLP, Natural Language Processing) 處理文本。(D) 強化學習 (RL, Reinforcement Learning) 主要用於決策制定。因此,CNN 是物體檢測最核心的技術基礎。
#25
★★★
影像分割技術在電腦視覺中通常應用於哪一種領域,特別是在將影 像中的不同部分進行細分和識別方面?
答案解析
影像分割 (Image Segmentation) 的目標是對影像進行像素級的分類,為每個像素分配一個類別標籤,從而將影像精確地劃分成不同的區域。這項技術在許多領域都有重要應用,其中醫療影像分析 (Medical Image Analysis) 是最典型的應用之一。
在醫療影像(如 CT、MRI、X光)中,影像分割可用於:
- 精確地勾勒出腫瘤 (Tumor) 的邊界,以評估大小和位置。
- 分割出特定的器官 (Organ) 或組織 (Tissue),進行體積測量或形態學分析。
- 識別病灶區域 (Lesion Area)。
這些分割結果對疾病診斷、手術規劃和治療監測至關重要。
(A) 文字生成屬於 NLP。(B) 影像分類是對整個影像。(C) 影像修復 (Image Inpainting) 是填補影像缺失部分。
在醫療影像(如 CT、MRI、X光)中,影像分割可用於:
- 精確地勾勒出腫瘤 (Tumor) 的邊界,以評估大小和位置。
- 分割出特定的器官 (Organ) 或組織 (Tissue),進行體積測量或形態學分析。
- 識別病灶區域 (Lesion Area)。
這些分割結果對疾病診斷、手術規劃和治療監測至關重要。
(A) 文字生成屬於 NLP。(B) 影像分類是對整個影像。(C) 影像修復 (Image Inpainting) 是填補影像缺失部分。
#26
★★★
在電腦視覺中,邊緣檢測技術通常用於實現什麼目的,特別是在識 別和定位影像中的目標物體方面?
答案解析
邊緣檢測 (Edge Detection) 是識別影像中亮度或顏色強度發生顯著變化的點的過程。這些變化通常發生在物體的邊界處。
雖然邊緣檢測本身並不直接完成目標檢測 (Object Detection) 的所有工作(目標檢測還需要識別物體類別並給出精確的邊界框),但檢測到的邊緣資訊提供了關於物體形狀、輪廓和可能位置的重要線索。因此,邊緣檢測是許多目標檢測、影像分割和物體識別演算法中的一個基礎且關鍵的預處理步驟或組成部分。可以說,邊緣檢測服務於目標檢測等更高級的視覺任務。
(A) 強化學習用於決策。(B) 影像增強是改善影像品質。(D) 影像變換 (Image Transformation) 指幾何操作或色彩空間轉換等。因此,選項 C 是邊緣檢測最相關的應用目的。
雖然邊緣檢測本身並不直接完成目標檢測 (Object Detection) 的所有工作(目標檢測還需要識別物體類別並給出精確的邊界框),但檢測到的邊緣資訊提供了關於物體形狀、輪廓和可能位置的重要線索。因此,邊緣檢測是許多目標檢測、影像分割和物體識別演算法中的一個基礎且關鍵的預處理步驟或組成部分。可以說,邊緣檢測服務於目標檢測等更高級的視覺任務。
(A) 強化學習用於決策。(B) 影像增強是改善影像品質。(D) 影像變換 (Image Transformation) 指幾何操作或色彩空間轉換等。因此,選項 C 是邊緣檢測最相關的應用目的。
#27
★★★
在自然語言處理領域中,以下哪一種演算法被用於將句子中的詞語進 行分割和標註?
答案解析
自然語言處理 (NLP, Natural Language Processing) 中的序列標註 (Sequence Labeling) 任務是為輸入序列(如句子)中的每個元素(如詞語)分配一個標籤。常見的序列標註任務包括:
- 分詞 (Word Segmentation):將連續的字元序列切分成詞語(尤其在中文等無空格語言中)。
- 詞性標註 (Part-of-Speech Tagging, POS Tagging):為每個詞語標註其語法類別(如名詞、動詞、形容詞)。
(C) 隱馬可夫模型 (HMM, Hidden Markov Model) 是一種經典的生成式機率圖模型,由於其能夠對序列數據進行建模,在傳統 NLP 中被廣泛用於分詞和詞性標註等序列標註任務。
(A) LSTM 和 (D) RNN 是深度學習模型,也常用於序列標註,且效果通常優於 HMM,但 HMM 是該領域的基礎演算法之一,且題目描述符合其應用場景。(B) TF-IDF (Term Frequency-Inverse Document Frequency) 用於計算詞語權重,不是序列標註演算法。
- 分詞 (Word Segmentation):將連續的字元序列切分成詞語(尤其在中文等無空格語言中)。
- 詞性標註 (Part-of-Speech Tagging, POS Tagging):為每個詞語標註其語法類別(如名詞、動詞、形容詞)。
(C) 隱馬可夫模型 (HMM, Hidden Markov Model) 是一種經典的生成式機率圖模型,由於其能夠對序列數據進行建模,在傳統 NLP 中被廣泛用於分詞和詞性標註等序列標註任務。
(A) LSTM 和 (D) RNN 是深度學習模型,也常用於序列標註,且效果通常優於 HMM,但 HMM 是該領域的基礎演算法之一,且題目描述符合其應用場景。(B) TF-IDF (Term Frequency-Inverse Document Frequency) 用於計算詞語權重,不是序列標註演算法。
#28
★★★
在自然語言處理中,詞嵌入技術主要用於什麼目的,以表示詞語之 間的語義關係?
答案解析
詞嵌入 (Word Embedding) 是自然語言處理 (NLP) 中將詞語從離散的符號表示(如 one-hot encoding)轉換為連續的、低維的、稠密的向量表示 (Vector Representation) 的技術。例如 Word2Vec、GloVe 等。
這種向量表示的主要優點是能夠捕捉詞語之間的語義 (Semantic) 和句法 (Syntactic) 關係。在學習到的向量空間中,語義相近的詞語(如「貓」和「狗」,或「跑」和「走」)其對應的向量在空間中的距離也較近。這種表示方式使得計算機能夠更好地理解詞語的含義和它們之間的聯繫,是許多下游 NLP 任務(如文本分類、情感分析、機器翻譯)的重要基礎。
(A) 分詞是將文本切分成詞。(C) 文本生成是創建文本。(D) 語音識別處理語音。
這種向量表示的主要優點是能夠捕捉詞語之間的語義 (Semantic) 和句法 (Syntactic) 關係。在學習到的向量空間中,語義相近的詞語(如「貓」和「狗」,或「跑」和「走」)其對應的向量在空間中的距離也較近。這種表示方式使得計算機能夠更好地理解詞語的含義和它們之間的聯繫,是許多下游 NLP 任務(如文本分類、情感分析、機器翻譯)的重要基礎。
(A) 分詞是將文本切分成詞。(C) 文本生成是創建文本。(D) 語音識別處理語音。
#29
★★★
BERT 模型在自然語言處理中的主要應用是什麼,特別是在理解和 生成語言方面?
答案解析
BERT (Bidirectional Encoder Representations from Transformers) 是一種基於 Transformer 編碼器 (Encoder) 架構的預訓練語言模型 (Pre-trained Language Model)。它通過在海量文本數據上進行預訓練(主要任務是掩碼語言模型 Masked Language Model, MLM 和下一句預測 Next Sentence Prediction, NSP),學習到了深層次的、雙向的上下文語義表示 (Semantic Representation)。
BERT 的核心優勢在於其強大的語言理解能力。通過預訓練獲得的通用語言知識,可以通過微調 (Fine-tuning) 輕鬆遷移到各種下游 NLP 任務,如文本分類、命名實體識別 (NER)、問答系統 (QA) 等,並在這些任務上取得了突破性的成果。
(A) BERT 的架構主要是編碼器,其強項在於理解而非生成(生成任務通常由 GPT 等基於解碼器的模型主導)。(B) 分詞是 NLP 的預處理步驟。(D) 語音合成處理語音。因此,選項 C 最準確。
BERT 的核心優勢在於其強大的語言理解能力。通過預訓練獲得的通用語言知識,可以通過微調 (Fine-tuning) 輕鬆遷移到各種下游 NLP 任務,如文本分類、命名實體識別 (NER)、問答系統 (QA) 等,並在這些任務上取得了突破性的成果。
(A) BERT 的架構主要是編碼器,其強項在於理解而非生成(生成任務通常由 GPT 等基於解碼器的模型主導)。(B) 分詞是 NLP 的預處理步驟。(D) 語音合成處理語音。因此,選項 C 最準確。
#30
★★★
在情感分析的應用中,主要用於標註情感極性的技術是什麼,以便 識別文本中的情感傾向?
答案解析
情感分析 (Sentiment Analysis),也稱為意見挖掘 (Opinion Mining),旨在識別和提取文本資料中表達的主觀資訊,特別是說話者或作者的態度、評價、觀點和情感 (Emotion)。
判斷文本的情感極性 (Sentiment Polarity)(例如,正面、負面、中性)是情感分析中最常見的任務。從技術角度看,這通常被建模為一個文本分類 (Text Classification) 問題,即為給定的文本分配一個預定義的情感類別標籤。
因此,無論是人工準備訓練數據的過程(需要對文本進行情感標註),還是模型最終輸出的結果(預測文本的情感標籤),「標註」 (Labeling/Annotation) 都是描述這個核心過程的關鍵詞。
(A) 分詞是預處理。(B) 詞嵌入是表示方法。(D) 聚類是非監督式的,而情感分析通常是監督式的(需要標註數據)。
判斷文本的情感極性 (Sentiment Polarity)(例如,正面、負面、中性)是情感分析中最常見的任務。從技術角度看,這通常被建模為一個文本分類 (Text Classification) 問題,即為給定的文本分配一個預定義的情感類別標籤。
因此,無論是人工準備訓練數據的過程(需要對文本進行情感標註),還是模型最終輸出的結果(預測文本的情感標籤),「標註」 (Labeling/Annotation) 都是描述這個核心過程的關鍵詞。
(A) 分詞是預處理。(B) 詞嵌入是表示方法。(D) 聚類是非監督式的,而情感分析通常是監督式的(需要標註數據)。
#31
★★★
在機器翻譯的應用中,以下哪一種模型類型被廣泛使用,以實現不 同語言之間的自動翻譯?
答案解析
機器翻譯 (Machine Translation, MT) 是將一種自然語言(源語言)的文本自動轉換為另一種自然語言(目標語言)的文本。
早期的神經機器翻譯 (Neural Machine Translation, NMT) 模型廣泛採用基於循環神經網路 (RNN, Recurrent Neural Network) 的序列到序列 (Sequence-to-Sequence, Seq2Seq) 架構。Seq2Seq 模型通常包含一個編碼器 (Encoder) RNN(讀取源語言句子並生成上下文向量)和一個解碼器 (Decoder) RNN(根據上下文向量生成目標語言句子)。由於標準 RNN 難以處理長序列的依賴關係,其變體如長短期記憶網路 (LSTM, Long Short-Term Memory) 和門控循環單元 (GRU, Gated Recurrent Unit) 更為常用。
雖然現在基於 Transformer 的模型已成為 NMT 的主流,但 RNN/ LSTM 仍然是理解其發展和基礎的重要模型類型。(A) CNN 主要用於影像。(C, D) 是傳統機器學習模型,不直接用於 NMT。
早期的神經機器翻譯 (Neural Machine Translation, NMT) 模型廣泛採用基於循環神經網路 (RNN, Recurrent Neural Network) 的序列到序列 (Sequence-to-Sequence, Seq2Seq) 架構。Seq2Seq 模型通常包含一個編碼器 (Encoder) RNN(讀取源語言句子並生成上下文向量)和一個解碼器 (Decoder) RNN(根據上下文向量生成目標語言句子)。由於標準 RNN 難以處理長序列的依賴關係,其變體如長短期記憶網路 (LSTM, Long Short-Term Memory) 和門控循環單元 (GRU, Gated Recurrent Unit) 更為常用。
雖然現在基於 Transformer 的模型已成為 NMT 的主流,但 RNN/ LSTM 仍然是理解其發展和基礎的重要模型類型。(A) CNN 主要用於影像。(C, D) 是傳統機器學習模型,不直接用於 NMT。
#32
★★★
在自然語言處理中,文本分類的主要目的是什麼,特別是在將文本 內容組織到不同預定義類別的過程中?
答案解析
文本分類 (Text Classification) 是自然語言處理 (NLP, Natural Language Processing) 中的一項基本且重要的任務。它的核心目標是根據文本的內容,將其自動分配到一個或多個預先設定好的、有意義的類別 (Category) 或標籤 (Label) 中。例如:
- 新聞主題分類:將新聞文章歸類到「體育」、「政治」、「科技」、「娛樂」等主題。
- 垃圾郵件檢測:將郵件分為「垃圾郵件」或「非垃圾郵件」。
- 意圖識別:判斷使用者輸入的查詢屬於哪個意圖(如「查詢天氣」、「播放音樂」)。
(A) 分詞是預處理。(B) 情感分析可以看作是文本分類的一種特殊應用(將文本分為正面/負面/中性等情感類別),但文本分類本身涵蓋更廣泛的應用。(D) 資訊檢索 (Information Retrieval) 是根據查詢找到相關文件,與分類不同。因此,選項 C 最準確地描述了文本分類的主要目的。
- 新聞主題分類:將新聞文章歸類到「體育」、「政治」、「科技」、「娛樂」等主題。
- 垃圾郵件檢測:將郵件分為「垃圾郵件」或「非垃圾郵件」。
- 意圖識別:判斷使用者輸入的查詢屬於哪個意圖(如「查詢天氣」、「播放音樂」)。
(A) 分詞是預處理。(B) 情感分析可以看作是文本分類的一種特殊應用(將文本分為正面/負面/中性等情感類別),但文本分類本身涵蓋更廣泛的應用。(D) 資訊檢索 (Information Retrieval) 是根據查詢找到相關文件,與分類不同。因此,選項 C 最準確地描述了文本分類的主要目的。
#33
★★★
LSTM 模型在自然語言處理中常用於什麼應用,特別是在處理和生 成序列數據的任務中?
答案解析
長短期記憶網路 (LSTM, Long Short-Term Memory) 是一種特殊的循環神經網路 (RNN),設計用來解決標準 RNN 在處理長序列數據 (Sequential Data) 時遇到的梯度消失 (Vanishing Gradient) 和梯度爆炸 (Exploding Gradient) 問題。
由於其能夠有效地學習和記憶序列中的長期依賴關係,LSTM 非常適用於各種序列建模 (Sequence Modeling) 任務。在自然語言處理 (NLP) 領域,語言數據本質上就是序列數據(詞語或字元的序列),因此 LSTM 被廣泛應用於:
- 語言模型 (Language Modeling)
- 機器翻譯 (Machine Translation)
- 文本生成 (Text Generation)
- 情感分析 (Sentiment Analysis)
- 序列標註 (Sequence Labeling),如命名實體識別 (NER)
同時,它也適用於其他領域的時間序列數據 (Time Series Data) 處理,如語音識別 (Speech Recognition) 或股票預測 (Stock Prediction)。
(A) 影像分類通常用 CNN。(C) 特徵提取是過程,不是應用。(D) 降維用於減少特徵。
由於其能夠有效地學習和記憶序列中的長期依賴關係,LSTM 非常適用於各種序列建模 (Sequence Modeling) 任務。在自然語言處理 (NLP) 領域,語言數據本質上就是序列數據(詞語或字元的序列),因此 LSTM 被廣泛應用於:
- 語言模型 (Language Modeling)
- 機器翻譯 (Machine Translation)
- 文本生成 (Text Generation)
- 情感分析 (Sentiment Analysis)
- 序列標註 (Sequence Labeling),如命名實體識別 (NER)
同時,它也適用於其他領域的時間序列數據 (Time Series Data) 處理,如語音識別 (Speech Recognition) 或股票預測 (Stock Prediction)。
(A) 影像分類通常用 CNN。(C) 特徵提取是過程,不是應用。(D) 降維用於減少特徵。
#34
★★★
在自然語言處理中,命名實體識別(NER)的主要用途是什麼,特 別是在識別和分類文本中的專有名詞時?
答案解析
命名實體識別 (NER, Named Entity Recognition) 是自然語言處理 (NLP) 和資訊提取 (Information Extraction) 的一項基礎任務。它的目標是定位文本中提及的命名實體 (Named Entity)(通常是專有名詞)的邊界,並將它們分類到預定義的類別中。
常見的實體類別包括:
- 人名 (Person, PER)
- 組織機構名 (Organization, ORG)
- 地名/位置 (Location/Geopolitical Entity, LOC/GPE)
- 時間表達式(日期 Date, 時間 Time)
- 數值表達式(貨幣 Money, 百分比 Percent)
NER 對於理解文本內容、構建知識圖譜 (Knowledge Graph)、問答系統 (QA) 等應用至關重要。
(A) 關鍵詞提取 (Keyword Extraction) 目標不同。(B) 這是文本分類。(D) 這是文本生成。
常見的實體類別包括:
- 人名 (Person, PER)
- 組織機構名 (Organization, ORG)
- 地名/位置 (Location/Geopolitical Entity, LOC/GPE)
- 時間表達式(日期 Date, 時間 Time)
- 數值表達式(貨幣 Money, 百分比 Percent)
NER 對於理解文本內容、構建知識圖譜 (Knowledge Graph)、問答系統 (QA) 等應用至關重要。
(A) 關鍵詞提取 (Keyword Extraction) 目標不同。(B) 這是文本分類。(D) 這是文本生成。
#35
★★★
在自然語言處理中,TF-IDF 技術的主要作用是什麼,以衡量詞語在 文本中的重要性?
答案解析
TF-IDF (Term Frequency-Inverse Document Frequency) 是一種用於資訊檢索 (Information Retrieval) 與文本挖掘 (Text Mining) 的常用加權技術。它是一種統計方法,用以評估一個詞語對於一個文件集(語料庫, Corpus)或其中一份文件的重要程度。
一個詞語的重要性隨着它在文件中出現的次數成正比增加(即詞頻, TF),但同時會隨着它在語料庫中出現的頻率成反比下降(即逆文件頻率, IDF)。IDF 的主要思想是,如果一個詞語在很多文件中都出現,那麼它可能是一個通用詞語,對於區分特定文件的重要性較低;反之,如果一個詞語只在少數文件中出現,則它可能更能代表這些文件的內容。
TF-IDF 將這兩者結合起來,計算出一個詞語在特定文件中的相對重要性分數。
(A) 分詞是預處理。(C) 文本生成是創建。(D) 音素標註處理語音。
一個詞語的重要性隨着它在文件中出現的次數成正比增加(即詞頻, TF),但同時會隨着它在語料庫中出現的頻率成反比下降(即逆文件頻率, IDF)。IDF 的主要思想是,如果一個詞語在很多文件中都出現,那麼它可能是一個通用詞語,對於區分特定文件的重要性較低;反之,如果一個詞語只在少數文件中出現,則它可能更能代表這些文件的內容。
TF-IDF 將這兩者結合起來,計算出一個詞語在特定文件中的相對重要性分數。
(A) 分詞是預處理。(C) 文本生成是創建。(D) 音素標註處理語音。
#36
★★★
在自然語言處理中,用於測試語言模型效能的常見指標是什麼,特 別是在衡量模型預測能力方面?
答案解析
語言模型 (Language Model, LM) 的主要任務是估計一個詞語序列(句子)出現的機率。評估 LM 效能的一個常用且重要的指標是困惑度 (Perplexity, PPL)。
困惑度可以被直觀地理解為語言模型在預測下一個詞時平均有多少個可能的選擇。它基本上是測試集中每個詞的平均機率的倒數(通常基於交叉熵損失計算)。困惑度越低,表示語言模型對測試數據的機率估計越準確,模型對序列的預測能力越強,效能越好。
(A) 精確率 (Precision) 和 (B) 召回率 (Recall) 是分類任務常用的評估指標。(D) 特徵提取是過程。
困惑度可以被直觀地理解為語言模型在預測下一個詞時平均有多少個可能的選擇。它基本上是測試集中每個詞的平均機率的倒數(通常基於交叉熵損失計算)。困惑度越低,表示語言模型對測試數據的機率估計越準確,模型對序列的預測能力越強,效能越好。
(A) 精確率 (Precision) 和 (B) 召回率 (Recall) 是分類任務常用的評估指標。(D) 特徵提取是過程。
#37
★★★
在自然語言處理的領域中,以下哪一種模型被廣泛用於語音識別, 特別是在將語音信號轉換為文字的過程中?
答案解析
語音識別 (Speech Recognition),或稱自動語音識別 (Automatic Speech Recognition, ASR),是將人類語音轉換為文字的技術。
傳統 ASR 系統通常包含聲學模型 (Acoustic Model) 和語言模型 (Language Model)。隱馬可夫模型 (HMM, Hidden Markov Model) 在過去幾十年中一直是構建聲學模型的主流方法。它用於對語音的基本單元(如音素 Phoneme)及其時間演變過程進行機率建模。通常 HMM 會與高斯混合模型 (GMM, Gaussian Mixture Model) 結合使用(GMM-HMM 系統)來對每個 HMM 狀態的聲學特徵分佈進行建模。
雖然現代 ASR 系統更多採用深度學習方法(如基於 RNN、CNN、Transformer 的端到端模型),但 HMM 仍然是語音識別歷史上和理論上非常重要的模型。
(A, B, D) 是機器學習中的其他演算法,不直接是語音識別的核心模型。
傳統 ASR 系統通常包含聲學模型 (Acoustic Model) 和語言模型 (Language Model)。隱馬可夫模型 (HMM, Hidden Markov Model) 在過去幾十年中一直是構建聲學模型的主流方法。它用於對語音的基本單元(如音素 Phoneme)及其時間演變過程進行機率建模。通常 HMM 會與高斯混合模型 (GMM, Gaussian Mixture Model) 結合使用(GMM-HMM 系統)來對每個 HMM 狀態的聲學特徵分佈進行建模。
雖然現代 ASR 系統更多採用深度學習方法(如基於 RNN、CNN、Transformer 的端到端模型),但 HMM 仍然是語音識別歷史上和理論上非常重要的模型。
(A, B, D) 是機器學習中的其他演算法,不直接是語音識別的核心模型。
#38
★★★
在機器翻譯的應用中,以下哪一種模型類型被廣泛使用,特別是在 實現不同語言之間的自動翻譯功能方面?
答案解析
(此題與 Q31 重複,答案和解析相同)
機器翻譯 (Machine Translation, MT) 是將一種自然語言(源語言)的文本轉換為另一種自然語言(目標語言)的文本。
早期的神經機器翻譯 (Neural Machine Translation, NMT) 模型廣泛採用基於循環神經網路 (RNN, Recurrent Neural Network) 的序列到序列 (Sequence-to-Sequence, Seq2Seq) 架構。Seq2Seq 模型通常包含一個編碼器 (Encoder) RNN(讀取源語言句子並生成上下文向量)和一個解碼器 (Decoder) RNN(根據上下文向量生成目標語言句子)。由於標準 RNN 難以處理長序列的依賴關係,其變體如長短期記憶網路 (LSTM, Long Short-Term Memory) 和門控循環單元 (GRU, Gated Recurrent Unit) 更為常用。
雖然現在基於 Transformer 的模型已成為 NMT 的主流,但 RNN/LSTM 仍然是理解其發展和基礎的重要模型類型。(B) CNN 主要用於影像。(C) SVM 用於分類回歸。(D) 潛在狄利克雷分配 (LDA, Latent Dirichlet Allocation) 用於主題建模 (Topic Modeling)。
機器翻譯 (Machine Translation, MT) 是將一種自然語言(源語言)的文本轉換為另一種自然語言(目標語言)的文本。
早期的神經機器翻譯 (Neural Machine Translation, NMT) 模型廣泛採用基於循環神經網路 (RNN, Recurrent Neural Network) 的序列到序列 (Sequence-to-Sequence, Seq2Seq) 架構。Seq2Seq 模型通常包含一個編碼器 (Encoder) RNN(讀取源語言句子並生成上下文向量)和一個解碼器 (Decoder) RNN(根據上下文向量生成目標語言句子)。由於標準 RNN 難以處理長序列的依賴關係,其變體如長短期記憶網路 (LSTM, Long Short-Term Memory) 和門控循環單元 (GRU, Gated Recurrent Unit) 更為常用。
雖然現在基於 Transformer 的模型已成為 NMT 的主流,但 RNN/LSTM 仍然是理解其發展和基礎的重要模型類型。(B) CNN 主要用於影像。(C) SVM 用於分類回歸。(D) 潛在狄利克雷分配 (LDA, Latent Dirichlet Allocation) 用於主題建模 (Topic Modeling)。
#39
★★★
生成對抗網路(GAN)在生成式 AI 中的主要應用是什麼,特別是 在創建新的影像方面?
答案解析
生成式 AI (Generative AI) 指的是能夠創造新的、原創內容的人工智能系統。生成對抗網路 (GAN, Generative Adversarial Network) 是生成式 AI 領域中最著名和最成功的模型之一,尤其在影像生成 (Image Generation) 方面取得了令人矚目的成就。
GAN 通過生成器 (Generator) 和鑑別器 (Discriminator) 之間的對抗性學習過程,能夠學習真實數據的複雜分佈,並生成高度逼真、多樣化的新影像,例如生成人臉、風景、藝術作品等。此外,GAN 也可用於影像風格轉換、超解析度等任務。
(A) 影像分類是判別任務。(C) GAN 也可用於文本生成,但其在影像生成上的應用更為突出和典型。(D) 數據增強可以利用生成模型,但不是 GAN 的主要應用目標。
GAN 通過生成器 (Generator) 和鑑別器 (Discriminator) 之間的對抗性學習過程,能夠學習真實數據的複雜分佈,並生成高度逼真、多樣化的新影像,例如生成人臉、風景、藝術作品等。此外,GAN 也可用於影像風格轉換、超解析度等任務。
(A) 影像分類是判別任務。(C) GAN 也可用於文本生成,但其在影像生成上的應用更為突出和典型。(D) 數據增強可以利用生成模型,但不是 GAN 的主要應用目標。
#40
★★★
生成模型在生成式 AI 中的主要目的是什麼,特別是在創建與訓練數據相似的新數據方面?
答案解析
生成式 AI (Generative AI) 的核心在於使用生成模型 (Generative Model)。與學習如何區分不同類別數據的判別模型 (Discriminative Model) 不同,生成模型的目標是學習訓練數據的潛在機率分佈 P(X),或者學習輸入 X 和輸出 Y 的聯合機率分佈 P(X, Y)。
通過學習這個分佈,生成模型就能夠從該分佈中進行採樣,生成 (Generate) 全新的、與原始訓練數據具有相似統計特性和結構的數據樣本 (Data Samples)。這些新數據可以是影像、文本、音樂、程式碼等各種形式。
(A) 特徵提取是過程。(C) 分類是判別任務。(D) 聚類是非監督發現結構。
通過學習這個分佈,生成模型就能夠從該分佈中進行採樣,生成 (Generate) 全新的、與原始訓練數據具有相似統計特性和結構的數據樣本 (Data Samples)。這些新數據可以是影像、文本、音樂、程式碼等各種形式。
(A) 特徵提取是過程。(C) 分類是判別任務。(D) 聚類是非監督發現結構。
#41
★★★
在生成文本的過程中,以下哪一種模型被廣泛使用,以實現自然流 暢的文本生成?
答案解析
(此題與 Q43 相似)
GPT (Generative Pre-trained Transformer) 系列模型是基於 Transformer 架構的大型語言模型 (Large Language Model, LLM),在生成自然語言文本 (Natural Language Text Generation) 方面表現尤為突出。它們能夠理解上下文並生成連貫、流暢、語義豐富且多樣化的文本,是當前文本生成領域最先進、最廣泛使用的模型之一。
(A) CNN 主要用於影像。(B) GAN 主要用於影像生成,雖然也有文本 GAN,但不如 GPT 常用。(D) RNN (包括 LSTM/ GRU) 也能生成文本,但在捕捉長距離依賴和生成品質方面通常不如基於 Transformer 的模型。
GPT (Generative Pre-trained Transformer) 系列模型是基於 Transformer 架構的大型語言模型 (Large Language Model, LLM),在生成自然語言文本 (Natural Language Text Generation) 方面表現尤為突出。它們能夠理解上下文並生成連貫、流暢、語義豐富且多樣化的文本,是當前文本生成領域最先進、最廣泛使用的模型之一。
(A) CNN 主要用於影像。(B) GAN 主要用於影像生成,雖然也有文本 GAN,但不如 GPT 常用。(D) RNN (包括 LSTM/ GRU) 也能生成文本,但在捕捉長距離依賴和生成品質方面通常不如基於 Transformer 的模型。
#42
★★★
在生成式 AI 中,以下哪一種技術常用於生成音樂,特別是創作具 有連貫性和旋律性的音樂片段?
#43
★★★
在生成式 AI 中,以下哪一種技術常用於生成自然語言文本,特別 是在創建連貫且有意義的句子方面?
答案解析
(此題與 Q41 基本相同,答案和解析類似)
GPT (Generative Pre-trained Transformer) 模型是目前生成自然語言文本 (Natural Language Text Generation) 的主流技術。它基於 Transformer 架構,利用預訓練和自注意力機制 (Self-Attention Mechanism),能夠有效地捕捉文本中的長距離依賴關係,生成連貫、流暢且符合語法和語義的文本。
(A) RNN 和 (D) LSTM 也能生成文本,但效果通常不如 GPT。(B) CNN 主要應用於影像。
GPT (Generative Pre-trained Transformer) 模型是目前生成自然語言文本 (Natural Language Text Generation) 的主流技術。它基於 Transformer 架構,利用預訓練和自注意力機制 (Self-Attention Mechanism),能夠有效地捕捉文本中的長距離依賴關係,生成連貫、流暢且符合語法和語義的文本。
(A) RNN 和 (D) LSTM 也能生成文本,但效果通常不如 GPT。(B) CNN 主要應用於影像。
#44
★★★
在生成對抗網路(GAN)中,鑑別器的主要作用是什麼,特別是在 區分真實數據和生成數據方面?
答案解析
生成對抗網路 (GAN, Generative Adversarial Network) 由兩個核心部分組成:
1. 生成器 (Generator):負責學習真實數據的分佈,並嘗試生成看起來像真實數據的假數據。
2. 鑑別器 (Discriminator):負責學習區分輸入的數據是來自真實數據集,還是由生成器產生的假數據。
鑑別器的目標是盡可能準確地判斷數據的來源(真實 vs. 生成),它就像一個評判者。它的判斷結果(例如,判斷為假數據的機率)會被用來計算損失,並通過反向傳播 (Backpropagation) 提供梯度 (Gradient) 信號(即反饋)給生成器,指導生成器改進其生成策略,以產生更逼真的數據來"欺騙"鑑別器。
因此,鑑別器的主要作用是區分真假數據,並通過這個過程提供反饋給生成器。選項 B 準確描述了這兩點。(A) 鑑別器不直接訓練生成器,而是提供反饋。(C, D) 不是鑑別器在 GAN 中的核心作用。
1. 生成器 (Generator):負責學習真實數據的分佈,並嘗試生成看起來像真實數據的假數據。
2. 鑑別器 (Discriminator):負責學習區分輸入的數據是來自真實數據集,還是由生成器產生的假數據。
鑑別器的目標是盡可能準確地判斷數據的來源(真實 vs. 生成),它就像一個評判者。它的判斷結果(例如,判斷為假數據的機率)會被用來計算損失,並通過反向傳播 (Backpropagation) 提供梯度 (Gradient) 信號(即反饋)給生成器,指導生成器改進其生成策略,以產生更逼真的數據來"欺騙"鑑別器。
因此,鑑別器的主要作用是區分真假數據,並通過這個過程提供反饋給生成器。選項 B 準確描述了這兩點。(A) 鑑別器不直接訓練生成器,而是提供反饋。(C, D) 不是鑑別器在 GAN 中的核心作用。
#45
★★★
在生成式 AI 中,為了提高生成文本的品質,通常會採用哪一種方 法,特別是在使用預訓練模型的基礎上進行調整?
答案解析
預訓練模型 (Pre-trained Model),如 GPT 或 BERT,已經在海量的通用文本數據上學習了豐富的語言知識和模式。為了讓這些模型在特定的下游任務(如特定風格的文本生成、特定領域的問答)上表現更好,常用的方法是微調 (Fine-tuning)。
微調指的是在預訓練模型的基礎上,使用與特定任務相關的、相對較小的標籤數據集進行進一步的訓練。在這個過程中,模型的參數 (Parameters) 會被輕微調整,以適應該任務的數據分佈和要求,從而提高在該任務上的效能和生成品質。
(A) 資料增強 (Data Augmentation) 是擴充數據的方法。(C) 提高數據量用於預訓練或微調,但微調本身是關鍵步驟。(D) 卷積層 (Convolutional Layer) 主要用於 CNN。因此,選項 B 是利用預訓練模型提升特定任務品質的核心方法。
微調指的是在預訓練模型的基礎上,使用與特定任務相關的、相對較小的標籤數據集進行進一步的訓練。在這個過程中,模型的參數 (Parameters) 會被輕微調整,以適應該任務的數據分佈和要求,從而提高在該任務上的效能和生成品質。
(A) 資料增強 (Data Augmentation) 是擴充數據的方法。(C) 提高數據量用於預訓練或微調,但微調本身是關鍵步驟。(D) 卷積層 (Convolutional Layer) 主要用於 CNN。因此,選項 B 是利用預訓練模型提升特定任務品質的核心方法。
#46
★★★
在生成對抗網路(GAN)中,主要面臨的挑戰是什麼,特別是在模 型訓練過程中經常出現的不穩定性問題?
答案解析
生成對抗網路 (GAN, Generative Adversarial Network) 的訓練過程是一個生成器 (Generator) 和鑑別器 (Discriminator) 相互競爭、共同進化的動態博弈 (Game) 過程。這使得 GAN 的訓練相當困難且不穩定 (Unstable)。
主要的挑戰包括:
- 難以收斂 (Non-convergence):生成器和鑑別器之間的平衡很難達到,可能導致訓練過程震盪或無法收斂。
- 模式崩潰 (Mode Collapse):生成器可能只學會生成少數幾種能夠騙過鑑別器的樣本,無法覆蓋真實數據的多樣性。
- 梯度消失/爆炸 (Vanishing/Exploding Gradients):在訓練過程中可能出現梯度問題,導致學習停滯或發散。
- 鑑別器過強或過弱:如果鑑別器太強,生成器的梯度可能消失;如果太弱,生成器無法得到有效指導。
因此,維持兩者之間的平衡是 GAN 訓練中的核心挑戰,導致訓練不穩定。
(A) GAN 通常是非監督的,不需要數據標註。(C) 特徵提取是過程。(D) 訓練速度慢也是問題,但不穩定性是更根本的挑戰。
主要的挑戰包括:
- 難以收斂 (Non-convergence):生成器和鑑別器之間的平衡很難達到,可能導致訓練過程震盪或無法收斂。
- 模式崩潰 (Mode Collapse):生成器可能只學會生成少數幾種能夠騙過鑑別器的樣本,無法覆蓋真實數據的多樣性。
- 梯度消失/爆炸 (Vanishing/Exploding Gradients):在訓練過程中可能出現梯度問題,導致學習停滯或發散。
- 鑑別器過強或過弱:如果鑑別器太強,生成器的梯度可能消失;如果太弱,生成器無法得到有效指導。
因此,維持兩者之間的平衡是 GAN 訓練中的核心挑戰,導致訓練不穩定。
(A) GAN 通常是非監督的,不需要數據標註。(C) 特徵提取是過程。(D) 訓練速度慢也是問題,但不穩定性是更根本的挑戰。
#47
★★★
GPT 模型在生成式 AI 中的全稱是什麼,特別是在描述其架構和功能時?
答案解析
GPT 是由 OpenAI 開發的一系列大型語言模型 (LLM) 的名稱縮寫。其全稱為 Generative Pre-trained Transformer。
這個名稱精確地反映了該模型的三個核心特點:
- Generative (生成式):表明該模型的主要功能是生成新的內容,特別是文本。
- Pre-trained (預訓練):指模型首先在海量的無標籤文本數據上進行了大規模的預訓練,學習了廣泛的語言知識和模式。
- Transformer (變換器):指其底層的神經網路架構採用了 Transformer 模型,特別是其解碼器 (Decoder) 部分,利用自注意力機制 (Self-Attention Mechanism) 來處理長距離依賴關係。
其他選項是對 GPT 全稱的錯誤解釋或縮寫。
這個名稱精確地反映了該模型的三個核心特點:
- Generative (生成式):表明該模型的主要功能是生成新的內容,特別是文本。
- Pre-trained (預訓練):指模型首先在海量的無標籤文本數據上進行了大規模的預訓練,學習了廣泛的語言知識和模式。
- Transformer (變換器):指其底層的神經網路架構採用了 Transformer 模型,特別是其解碼器 (Decoder) 部分,利用自注意力機制 (Self-Attention Mechanism) 來處理長距離依賴關係。
其他選項是對 GPT 全稱的錯誤解釋或縮寫。
#48
★★★
在生成式 AI 中,強化學習主要用於什麼目的,特別是在提升生成 數據的品質方面?
答案解析
強化學習 (RL, Reinforcement Learning),特別是基於人類反饋的強化學習 (RLHF, Reinforcement Learning from Human Feedback),在生成式 AI(尤其是大型語言模型 LLM)的對齊 (Alignment) 和優化中扮演著重要角色。
單純的預訓練或監督式微調可能無法完全捕捉到人類對於「好」的生成內容的複雜偏好(例如,有用性、無害性、真實性、風格等)。RLHF 通過以下步驟來解決這個問題:
1. 訓練一個獎勵模型 (Reward Model),該模型學習預測人類評分者會給予某個生成輸出的獎勵分數。
2. 使用強化學習演算法(如 PPO, Proximal Policy Optimization)來微調 LLM 的策略,使其生成的內容能夠最大化獎勵模型給出的分數。
這個過程通過引入明確的獎勵信號 (Reward Signal) 來指導生成模型,使其學習生成更高品質、更符合人類偏好的內容。
選項 A 和 C 都描述了這個過程,但 C 更側重於最終目標「提高生成數據的品質」。(B) 分類是判別任務。(D) 特徵提取是過程。
單純的預訓練或監督式微調可能無法完全捕捉到人類對於「好」的生成內容的複雜偏好(例如,有用性、無害性、真實性、風格等)。RLHF 通過以下步驟來解決這個問題:
1. 訓練一個獎勵模型 (Reward Model),該模型學習預測人類評分者會給予某個生成輸出的獎勵分數。
2. 使用強化學習演算法(如 PPO, Proximal Policy Optimization)來微調 LLM 的策略,使其生成的內容能夠最大化獎勵模型給出的分數。
這個過程通過引入明確的獎勵信號 (Reward Signal) 來指導生成模型,使其學習生成更高品質、更符合人類偏好的內容。
選項 A 和 C 都描述了這個過程,但 C 更側重於最終目標「提高生成數據的品質」。(B) 分類是判別任務。(D) 特徵提取是過程。
#49
★★★
在生成式 AI 中,通常用於生成影像的模型是什麼,特別是在創建 高品質和逼真的影像方面?
答案解析
(此題與 Q39 相似)
生成對抗網路 (GAN, Generative Adversarial Network) 是生成式 AI (Generative AI) 在影像生成 (Image Generation) 領域的代表性模型。它通過生成器和鑑別器的對抗訓練,能夠學習捕捉真實影像數據的複雜分佈,並生成具有高視覺保真度和逼真度的新影像。許多令人驚嘆的 AI 生成影像(如不存在的人臉、藝術畫作)都是基於 GAN 或其變體技術產生的。
近年來,擴散模型 (Diffusion Models) 在影像生成品質上取得了超越 GAN 的成果,但 GAN 仍然是該領域非常重要和常用的模型。
(B) CNN 主要用於分析影像。(C) RNN 主要用於序列數據。(D) SVM 主要用於分類。
生成對抗網路 (GAN, Generative Adversarial Network) 是生成式 AI (Generative AI) 在影像生成 (Image Generation) 領域的代表性模型。它通過生成器和鑑別器的對抗訓練,能夠學習捕捉真實影像數據的複雜分佈,並生成具有高視覺保真度和逼真度的新影像。許多令人驚嘆的 AI 生成影像(如不存在的人臉、藝術畫作)都是基於 GAN 或其變體技術產生的。
近年來,擴散模型 (Diffusion Models) 在影像生成品質上取得了超越 GAN 的成果,但 GAN 仍然是該領域非常重要和常用的模型。
(B) CNN 主要用於分析影像。(C) RNN 主要用於序列數據。(D) SVM 主要用於分類。
#50
★★★
在生成式 AI 的應用中,以下哪一種模型通常用於生成自然語言文 本,特別是在創建連貫且有意義的句子方面?
答案解析
自然語言文本生成 (Natural Language Text Generation) 是生成式 AI 的一個核心應用領域。
(D) 變換器模型 (Transformer Model),由 Google 在 2017 年提出,以其自注意力機制 (Self-Attention Mechanism) 徹底改變了自然語言處理 (NLP) 領域。基於 Transformer 架構的預訓練語言模型,特別是其解碼器部分(如 GPT 系列),在文本生成任務上表現極其出色,能夠生成高品質、連貫且符合上下文的文本。
(A) GAN 主要用於影像生成。(B) CNN 主要用於影像分析。(C) RNN/LSTM 雖然也能生成文本,但在捕捉長距離依賴和生成品質方面通常不如 Transformer 模型。因此,Transformer 模型(如 GPT)是當前文本生成的主流和最先進的模型。
(D) 變換器模型 (Transformer Model),由 Google 在 2017 年提出,以其自注意力機制 (Self-Attention Mechanism) 徹底改變了自然語言處理 (NLP) 領域。基於 Transformer 架構的預訓練語言模型,特別是其解碼器部分(如 GPT 系列),在文本生成任務上表現極其出色,能夠生成高品質、連貫且符合上下文的文本。
(A) GAN 主要用於影像生成。(B) CNN 主要用於影像分析。(C) RNN/LSTM 雖然也能生成文本,但在捕捉長距離依賴和生成品質方面通常不如 Transformer 模型。因此,Transformer 模型(如 GPT)是當前文本生成的主流和最先進的模型。